Biuro tłumaczeń translax – tłumaczenia dla firm
Inżynieria

Podwójne tłumaczenie: jak to działa?
Podwójne tłumaczenie, znane również jako dual translation, odnosi się do prezentowania niektórych treści w dwóch językach jednocześnie. Rozwiązanie to zyskuje na znaczeniu w kontekście globalizacji i dynamicznego rozwoju technologii językowej, umożliwiając użytkownikom łatwiejsze zrozumienie i poruszanie się po dokumentacji. Zazwyczaj najpierw podaje się tłumaczenie, a potem jego oryginalną wersję w nawiasie (lub odwrotnie). Przyjęta konwencja stosowana jest spójnie w całym projekcie.
Podwójne tłumaczenia w praktyce
1. Dokumentacja techniczna
Podwójne tłumaczenie dokumentacji technicznej odgrywa kluczową rolę w zapewnianiu zrozumiałości i jednoznaczności informacji przekazywanych użytkownikom urządzeń i oprogramowania. W dokumentacji technicznej, takiej jak instrukcje obsługi, instalacji, konfiguracji, podręczniki czy specyfikacje techniczne, precyzja języka jest niezbędna, aby uniknąć błędów, które mogłyby prowadzić do niewłaściwego użytkowania.
Znaczenie podwójnego tłumaczenia w dokumentacji urządzeń i oprogramowania:
- Redukcja błędów interpretacyjnych: podawanie (w dokumentacji) terminologii ekranowej w dwóch językach jednocześnie minimalizuje ryzyko błędnej interpretacji dokumentacji przez użytkowników w zestawieniu z tym, co naprawdę wyświetlane jest na ekranie pulpitu sterującego. Jest to szczególnie istotne w przypadku złożonych urządzeń lub systemów, które nie posiadają przetłumaczonego interfejsu i nie jest to w najbliższych planach.
- Przyspieszenie tłumaczenia dokumentacji: stosowanie podwójnego tłumaczenia wszystkich poleceń, nazw okien i przycisków ekranowych przyspiesza proces tłumaczenia dokumentacji, ponieważ nie musimy czekać na podmianę wszystkich zrzutów ekranowych w oryginalnej dokumentacji, ani lokalizować ich, jeśli nie ma na to czasu lub środków. Tradycyjne tłumaczenie spowodowałoby, że użytkownik dokumentacji dysponowałby przetłumaczonymi pojęciami, których nie widzi na ekranie. Jeśli interfejs został przetłumaczony w przeszłości (jeżeli tłumaczenia interfejsu nie zostałyby dostarczone, jako materiał referencyjny), to tłumaczenia w dokumentacji mogą być niespójne z tłumaczeniami wyświetlanymi na ekranie.
- Ułatwienie procesu szkoleniowego: szkolenie operatorów dysponujących dokumentacją urządzenia przetłumaczoną na ich język zawsze będą zmieszani, gdy komunikaty ekranowe w dokumentacji będą przetłumaczone, a na ekranie nie, lub są przetłumaczone, ale inaczej. Dzięki dual translation użytkownik rozumie, co oznacza dany przycisk i funkcja, nawet jeśli nie zna języka źródłowego. Co więcej, bez znajomości języka źródłowego będzie w stanie obsłużyć urządzenie, używając interfejsu, w jego oryginalnym języku.
Korzyści dla użytkowników wynikające z zastosowania tej techniki:
- Zwiększenie pewności siebie użytkowników: dzięki możliwości odniesienia się do znanych im terminów w ich ojczystym języku, użytkownicy czują się pewniej podczas korzystania z urządzeń i oprogramowania. Nawet w przypadku naturalnych niespójności między tłumaczeniem w dokumentacji a tym w interfejsie graficznym łatwiej jest operować urządzeniem.
- Optymalizacja procesów operacyjnych: przejrzysta i jednoznaczna dokumentacja przyczynia się do szybszego wdrażania nowych pracowników oraz redukcji czasu potrzebnego na rozwiązywanie problemów związanych z niejasnymi instrukcjami, które wyłącznie generują pytania i wątpliwości.
2. Umowy międzynarodowe
Znaczenie podwójnego tłumaczenia w tworzeniu przejrzystych umów i kontraktów jest nie do przecenienia. W kontekście prawa i negocjacji, precyzyjne zrozumienie terminologii jest kluczowe dla uniknięcia nieporozumień oraz potencjalnych sporów prawnych.
Dwujęzyczne tłumaczenia prawnicze najczęściej prezentowane są w układzie tabelarycznym dwu- lub trzykolumnowym. Dodatkowa kolumna najczęściej zawiera automatyczną numerację (uporządkowaną i nieuporządkowaną) akapitów, a kolejne kolumny zawierają odpowiadające sobie wersje językowe tej samej treści.
Należy pamiętać, że w umowie dwujęzycznej należy wskazać język obowiązujący (nadrzędny i wiążący prawnie), w przypadku wystąpienia rozbieżności merytorycznej między językami.
Rola podwójnego tłumaczenia w umowach międzynarodowych:
- Jasność i precyzja: umowy i kontrakty są często skomplikowane, zawierają liczne klauzule i warunki, które muszą być zrozumiane przez wszystkie strony. Podwójne tłumaczenie zapewnia, że każdy termin prawny i techniczny jest przedstawiony w obu językach, co redukuje ryzyko błędnej interpretacji.
- Ułatwienie negocjacji: podczas negocjacji międzynarodowych, strona posługująca się innym językiem może łatwo odnosić się do oryginalnych terminów w swoim języku ojczystym, co przyspiesza proces komunikacji.
- Zgodność z przepisami: w niektórych jurysdykcjach prawo wymaga, aby umowy były sporządzane w języku lokalnym. Podwójne tłumaczenie pozwala na spełnienie tych wymogów bez rezygnowania z wersji oryginalnej dokumentu.
Przykładem zastosowania tej techniki może być sytuacja, w której firma zawiera kontrakt z partnerem zagranicznym. Umowa sporządzona jednocześnie w języku angielskim i chińskim pozwala obu stronom na pełne zrozumienie zobowiązań i praw wynikających z dokumentu.
3. Materiały marketingowe
Podwójne tłumaczenie ma istotne znaczenie także w materiałach marketingowych, zwłaszcza przy zachowywaniu oryginalnych sloganów i nazw produktów. W kontekście międzynarodowych kampanii reklamowych kluczowe jest, aby przekaz był spójny i jednoznaczny niezależnie od języka docelowego. Dzięki podwójnemu tłumaczeniu możliwe jest prezentowanie oryginalnych haseł marketingowych wraz z ich tłumaczeniem, co pozwala na utrzymanie zamierzonego efektu komunikacyjnego i emocjonalnego.
Przykłady korzyści:
- Utrzymywanie oryginalnych sloganów: oryginalne slogany często mają specyficzne konotacje kulturowe lub grę słów, które mogą być trudne do przetłumaczenia. Podwójne tłumaczenie umożliwia użytkownikom zrozumienie pełnego znaczenia hasła bez utraty jego unikalnych cech.
- Nazwy produktów: wprowadzenie nowych produktów na rynki zagraniczne wymaga starannego zarządzania marką. Podwójne tłumaczenie pomaga zachować tożsamość marki, jednocześnie dostarczając niezbędnych informacji lokalnym konsumentom.
Podwójne tłumaczenie zwiększa zaufanie odbiorców do marki, pokazując zaangażowanie firmy w dostosowywanie się do różnych kultur i języków. Ułatwia to także proces decyzyjny, gdyż potencjalni klienci mają dostęp do pełniejszych informacji w swoim języku ojczystym, co minimalizuje ryzyko błędnej interpretacji treści marketingowej.
Dodatkowo podwójne tłumaczenie może również wpłynąć na postawy odbiorców wobec przekazów reklamowych. W rezultacie, zastosowanie tej techniki w materiałach marketingowych nie tylko wspiera efektywność działań promocyjnych, ale również wzmacnia globalną pozycję marki poprzez zwiększenie jej dostępności i zrozumiałości na różnych rynkach.
Podwójne tłumaczenie a transkreacja
Podwójne tłumaczenie materiałów marketingowych nie zastępuje transkreacji. Jest dobrym zamiennikiem, gdy klient nie jest jeszcze gotowy na transkreacje, lub jako wstęp do transkreacji. Po przygotowaniu Briefa, strategii komunikacji marki oraz strategii marketingowej i tak przygotowuje się oryginalną treść, która wymaga tłumaczenia na język transkreatora (najczęściej jest to copywriter, który nie zna biegle języka oryginalnego komunikatu), więc zastosowanie wersji podwójnej daje mu szerszy kontekst.
Korzyści z zastosowania podwójnego tłumaczenia w interfejsach GUI
Podwójne tłumaczenie w kontekście interfejsów GUI przynosi liczne korzyści, które przyczyniają się do poprawy jakości komunikacji oraz redukcji błędów językowych. Dzięki tej technice użytkownicy mogą korzystać z oprogramowania w sposób bardziej intuicyjny i zrozumiały, niezależnie od ich poziomu znajomości języka.
Minimalizacja błędów językowych
Jednym z głównych atutów podwójnego tłumaczenia jest redukcja błędów. Wprowadzenie terminologii w dwóch językach jednocześnie pozwala uniknąć nieporozumień wynikających z błędnych lub niejasnych tłumaczeń. Na przykład, w środowisku wielojęzycznym, gdzie różni użytkownicy mogą preferować różne wersje językowe oprogramowania, podwójne tłumaczenie zapewnia spójność i jednolitość komunikatów.
Przykład: Przycisk „Save” (Zapisz) – wyświetlany zarówno po angielsku, jak i po polsku, eliminuje ryzyko pomyłki i ułatwia użytkownikom korzystanie z funkcji programu.
Poprawa jednoznaczności
Podwójne tłumaczenie znacząco poprawia rozumienie interfejsu przez użytkowników. Dzięki jednoczesnemu wyświetlaniu terminów w dwóch językach użytkownicy mogą szybko odnosić się do znanych im pojęć, co przyspiesza proces nauki i adaptacji do nowego oprogramowania.
Wyzwania związane z podwójnym tłumaczeniem
Implementacja podwójnego tłumaczenia w interfejsach graficznych użytkownika (GUI) napotyka na szereg wyzwań, które mogą wpływać na jego efektywność i użyteczność. Jednym z kluczowych problemów jest zwiększona objętość tekstu.
Podwójne tłumaczenie wiąże się z koniecznością prezentacji terminów i komunikatów w dwóch językach jednocześnie. Oznacza to, że objętość tekstu może się znacząco zwiększyć, co prowadzi do kilku istotnych problemów:
- Przeciążenie informacyjne: większa ilość tekstu może przytłoczyć użytkownika, zwłaszcza jeśli jest on zmuszony do przyswajania dużej liczby informacji w krótkim czasie. Przykładem mogą być skomplikowane formularze lub narzędzia do zarządzania danymi, gdzie każdy dodatkowy element tekstowy może pogłębiać chaos informacyjny.
- Zmniejszenie czytelności: dłuższe opisy/fragmenty interfejsu w dwujęzycznej formie mogą powodować, że dokumentacja staje się mniej przejrzysta, a użytkownicy mogą mieć trudności z szybkim odnalezieniem potrzebnych informacji, co negatywnie wpływa na ich doświadczenia. W bilansie ogólnym lepiej wywołać drobną niedogodność niż uniemożliwić korzystanie z dokumentacji zostawiając pojęcia nieprzetłumaczone (w języku, którego nie zna operator) lub przetłumaczone „pojedynczo”, gdy na ekranie znajdują się inne teksty niepasujące do dokumentacji.
Najlepsze praktyki stosowania podwójnego tłumaczenia w interfejsach GUI
Implementacja podwójnego tłumaczenia w interfejsach graficznych użytkownika (GUI) wymaga świadomego podejścia do wyboru terminów, które powinny być zawsze prezentowane w dwóch językach. Kluczowe terminy, które są istotne dla funkcjonalności i zrozumiałości interfejsu, zasługują na szczególną uwagę.
Nie wszystkie elementy interfejsu wymagają podwójnego tłumaczenia. Konieczne jest zidentyfikowanie tych, które mają największy wpływ na doświadczenie użytkownika i mogą powodować zamieszanie, jeśli nie są odpowiednio przetłumaczone. Oto niektóre z najważniejszych kategorii terminów do uwzględnienia:
- Przyciski nawigacyjne: terminy takie jak „Zapisz”, „Anuluj”, „OK”, „Zamknij” są kluczowe dla płynnej nawigacji i powinny być zawsze dostępne w obu językach.
- Etykiety pól formularzy: pola takie jak „Imię”, „Nazwisko”, „Adres e-mail” powinny być dwujęzyczne, aby użytkownicy mogli łatwo rozpoznać, jakie informacje są wymagane.
- Komunikaty błędów i powiadomienia: precyzyjne zrozumienie komunikatów błędów jest krytyczne dla skutecznego rozwiązywania problemów. Tego typu informacje muszą być jasne i dostępne w obu językach.
- Instrukcje i wskazówki kontekstowe: wszystkie instrukcje dotyczące użytkowania aplikacji oraz wskazówki pomagające w nawigacji powinny być prezentowane dwujęzycznie, aby zapewnić pełną zrozumiałość.
- Opcje ustawień: terminy takie jak „Preferencje”, „Ustawienia użytkownika” itp. powinny być dwujęzyczne, aby użytkownicy mogli dostosować oprogramowanie do swoich potrzeb.
Przyszłość podwójnego tłumaczenia
Nowoczesne technologie językowe znacząco wpływają na efektywność i jakość podwójnego tłumaczenia interfejsów GUI. Oto kilka kluczowych technologii, które odgrywają istotną rolę:
- Pamięci tłumaczeniowe (TM):
-
- TM to bazy danych przechowujące wcześniej przetłumaczone fragmenty tekstu, które można ponownie wykorzystać w przyszłych projektach.
- Zastosowanie TM redukuje czas potrzebny na tłumaczenie identycznych lub podobnych fragmentów tekstu, zwiększając spójność terminologiczną.
- Narzędzia CAT (Computer Assisted Translation):
-
- Narzędzia CAT wspomagają tłumaczy poprzez automatyczne sugerowanie odpowiedników terminów oraz kontrolę jakości tłumaczeń.
- Integracja narzędzi CAT z systemami zarządzania treścią (CMS) ułatwia zarządzanie dużymi ilościami tekstu w różnych językach.
- Tłumaczenia neuronowe (NMT):
-
- NMT wykorzystuje sieci neuronowe do generowania bardziej naturalnych i dokładnych tłumaczeń.
- Tłumaczenia neuronowe wymagają szczególnej uważności ze strony osoby nadzorującej, ponieważ elementy interfejsu są zwykle bardzo krótkie i interpretacja ich zastosowania wymaga ludzkich umiejętności – NMT, ani AI nie potrafią ich zinterpretować.
Tłumaczenie „Open”, w zależności od miejsca występowania w interfejsie może być tłumaczone, jako „Otwórz” (polecenie/przycisk) oraz „Otwieranie” (nazwa okna). Oczywiście przykłady można mnożyć:
File
-
- Plik (jako element menu)
- Pliki (jako zbiór dokumentów w oknie)
Folder
-
- Folder (jako nazwa katalogu)
- Katalog (jako struktura organizacyjna)
Exit
-
- Wyjdź (jako polecenie zamknięcia aplikacji)
- Zamknij (jako polecenie zamknięcia okna)
Refresh
-
- Odśwież (jako polecenie/przycisk)
- Aktualizowanie (jako stan procesu)
Na przykład słowo „Start” może być „Początkiem”, „Uruchomieniem”, „Ekranem głównym” itd. Prawidłowo skonfigurowane i wykorzystywane TM, MT, NMT i AI radzą sobie z kontekstem, ale nie radzą sobie z interpretowaniem, w którym miejscu znajduje się dany tekst, dlaczego znajduje się w tym miejscu, jaki jest cel tego umiejscowienia, oraz co wydarzy się, gdy użytkownik wejdzie z nim w interakcję i np. kliknie, dotknie lub naciśnie dany element.
Podsumowanie
Podwójne tłumaczenia w praktyce są stosowane w różnych kontekstach, takich jak dokumentacja techniczna, umowy międzynarodowe oraz materiały marketingowe. W przypadku interfejsów GUI podwójne tłumaczenie pomaga minimalizować błędy językowe i poprawiać jednoznaczność komunikatów. Transkreacja jest alternatywą, która może być bardziej odpowiednia w niektórych przypadkach niż tradycyjne tłumaczenie.
Pomimo korzyści, takich jak zmniejszenie ryzyka nieporozumień, podwójne tłumaczenie napotyka również wyzwania, zwłaszcza w kontekście technologii NMT i AI, które nie zawsze potrafią rozpoznać specyfikę danego kontekstu. Przykłady różnorodnych tłumaczeń dla tego samego słowa (np. „Open” jako „Otwórz” lub „Otwieranie”) pokazują trudności związane z interpretacją miejsca i celu tekstu w interfejsie użytkownika.
Najlepsze praktyki obejmują dokładne rozważenie kontekstu oraz użycie podwójnego tłumaczenia tam, gdzie jest to najbardziej efektywne.
Kontakt

Profesjonalny OCR dokumentów: przewodnik dla tłumaczy i grafików
OCR w tłumaczeniach
Optyczne rozpoznawanie znaków (OCR) stało się nieodzownym narzędziem w arsenale współczesnych specjalistów branży tłumaczeniowej i projektowej. OCR umożliwia przekształcenie drukowanego, nieedytowalnego tekstu (np. ze skanu, zdjęcia lub tekstu zamienionego na krzywe) w format cyfrowy, edytowalny i przeszukiwalny poprzez konwersję wyglądu liter w tekst zakodowany maszynowo. Zupełnie, jak czowiek, który spogląda na stronę książki i przepisuje tekst do Worda.
Spis treści:
- Rodzaje OCR
- Transdoc z FineReader
- Draft_OCR – proste odwzorowanie
- Pełne odwzorowanie graficzne
- Korzyści płynące z doskonałego OCR
- Najlepsze praktyki OCR
- Optymalizacja plików DOCX dla narzędzi CAT
- Kluczowe wnioski
OCR stał się nieocenionym narzędziem dla tłumaczy. Niezależnie od typu dokumentu FineReader (podstawowe narzędzie do OCR) skutecznie skanuje i wyodrębnia tekst, usprawniając proces tłumaczenia. Czytając o FineReaderze (dla uproszczenia) zawsze należy przez to rozumieć Edytor OCR, który jest osobną aplikacją wchodzącą w skład programu FineReader. Należy jednak pamiętać, że OCR, mimo swojej skuteczności, nie jest bezbłędny. Drobne pomyłki w rozpoznawaniu mogą się zdarzać, dlatego konieczna jest uważna weryfikacja wyników.
OCR w projektowaniu graficznym
Graficy również docenili potencjał OCR, gdyż umożliwia szybkie wyodrębnianie tekstu z obrazów i manipulację nim w projektach. FineReader nie tylko przyspiesza pracę, ale również zwiększa precyzję (w porównaniu do ręcznego przepisywania). Graficy mogą skanować dokumenty, dostosowywać układ i ponownie wykorzystywać treść w spójny sposób, często bez kompromisów w zakresie oryginalnych elementów projektu.
Tłumacz, grafik, specjalista DTP?
OCR, niegdyś domena wąskiej grupy specjalistów DTP, stała się integralną częścią codziennej praktyki wielu profesjonalistów z sektora językowego.
Na rynku pojawiła się również grupa specjalistów skoncentrowanych wyłącznie na OCR, których umiejętności można postrzegać jako wyspecjalizowany, ale wąski wycinek kompetencji pełnoprawnego specjalisty DTP. Co więcej, sami tłumacze coraz częściej sięgają po narzędzia OCR, wykorzystując je zarówno na własne potrzeby, jak i wspierając tym swoich współpracowników.
Takie połączenie kompetencji sprawia, że granice między rolami zawodowymi zacierają się. W kontekście niniejszego artykułu „grafik” będzie stosowany wymiennie z „tłumaczem”, odnosząc się do każdego profesjonalisty, który w swojej pracy wykorzystuje technologię OCR.
Rodzaje OCR
Optyczne rozpoznawanie znaków oferuje wiele rozwiązań, z których każde ma swoje unikalne zalety i zastosowania. W OCR mamy do czynienia z różnorodnością opcji dostosowanych do specyficznych potrzeb użytkowników i projektów.
Transdoc: tabela dwujęzyczna
Transdoc to plik składający się z dwujęzycznej tabeli, idealny dla tłumaczy pracujących nad dokumentami wymagającymi zestawienia tekstów w dwóch językach. Główną zaletą takiego przygotowania pliku do tłumaczenia jest zdolność do generowania tabelarycznych reprezentacji treści w różnych językach, zachowując przy tym formatowanie i kontekst. Transdoc nie tylko umożliwia dokładne odwzorowanie tekstu w obu językach, ale również zapewnia, że oba teksty są starannie ułożone obok siebie. Funkcjonalność ta znacząco ułatwia proces tłumaczenia, pozwalając tłumaczom na łatwe porównywanie wersji źródłowej i docelowej podczas ostatniej kontroli jakości. Zwykle wykorzystuje się Transdoc, gdy klient końcowy życzy sobie przygotowania tłumaczenia w wersji dwujęzycznej (np. umowy) lub grafik klienta zajmie się składem DTP tłumaczenia, więc płacenie za odwzorowanie graficzne mijałoby się z celem.
Proste odwzorowanie: keep it simple
Proste odtworzenie układu graficznego to bezpośrednie i konkretne podejście do OCR, idealne do pracy z dokumentami, które nie wymagają oddania skomplikowanego formatowania. Metoda ta skupia się na dokładnym wyodrębnieniu tekstu, bez uwzględniania elementów takich jak czcionki, kolory czy złożone układy.
Przykładem zastosowania prostego odtworzenia może być konwersja protokołu ze spotkania z formatu papierowego na edytowalny. W tym przypadku kluczowe jest zapewnienie, że każda informacja zostanie precyzyjnie przetłumaczona. Chociaż metoda ta wydaje się prosta, wymaga dokładności. W tym przypadku odwzorowuje się oryginalne teksty z zachowaniem logicznego porządku oraz niezbędnych przepływów wraz z formatowaniem lokalnym takim, jak pogrubienia, podkreślenia, indeksy, pismo kursywne (i inne oczywiste wyróżnienia wewnątrz zdania, które mają zastosowanie funkcjonalne). Jeśli oryginalny dokument jest wielokolumnowy, zawiera różne fonty i ich wielkości, marginesy itd., to takie elementy nie zostaną oddane. Prosty OCR zapewnia określony standard przygotowania np. Format A4, Arial dla oryginalnych tekstów bezszeryfowych i Times New Roman dla szeryfowych. Nagłówki/tytuły wielkości 16 punktów, a reszta tekstów 12 punktów. Stałe marginesy 2,5 cm z każdej strony itd.
Pełne odwzorowanie układu i formatowania
Pełne odwzorowanie pozwala na dokładne odtworzenie wyglądu dokumentów. Metoda ta zachowuje nie tylko tekst, ale również style czcionek (jeśli są korporacyjne lub komercyjne, to klient musi je dostarczyć), rozmieszczenie obrazów i ogólny układ dokumentu. W zasadzie odwzorowanie pełne można nazwać roboczo odbudowaniem/odtworzeniem oryginalnego dokumentu.
W przypadku odwzorowania katalogu OCR musi wyciągnąć zarówno opisy produktów, jak i elementy wizualne, tworząc nowy dokument, który wygląda jak podobnie do oryginału.
Oczywiście często jest tak, że elementy graficzne trzeba ekstrahować ręcznie np. za pomocą Acrobata, Photoshopa, czy Illustratora, by stworzyć zasoby na potrzeby pełnego odwzorowania. Pamiętajmy, że pełne odwzorowanie nie kończy się na Wordzie. Często przygotowujemy tak zwany nowy oryginał w InDesign, by stworzyć dokument, który będzie miał „nowe” życie i potencjał rozwojowy (aktualizacyjny). W tym przypadku odwzorowujemy wszystko od formatu strony, przez fonty, kolory, marginesy, wcięcia, tabulatory, style, automatyzacje (odnośniki, spisy tabel, ilustracji, treści, indeksy…), grafiki itd.
Wybór scenariusza
Wybór odpowiedniego rodzaju OCR zależy od specyfiki projektu i potrzeb. Kluczowe pytania, które należy sobie zadać, to:
- Czy dokument jest głównie tekstowy, czy ma złożony projekt graficzny?
- Czy wymagana jest dwujęzyczna forma?
- Jak istotne są elementy wizualne dla zrozumienia treści?
- Jakie są wymagania odbiorców docelowych?
- Jakie są wymagania klienta końcowego?
- W jaki sposób będzie tłumaczony dany dokument (w CAT, czy bez CAT)?
- Czy po tłumaczeniu będzie wykonywany skład DTP i przygotowanie do druku, czy jest to dokument wewnętrzny?
Przy wyborze typu OCR kluczowe jest zrozumienie nie tylko technicznych aspektów dokumentu, ale również kontekstu jego wykorzystania. Czasem prostota jest najlepsza, innym razem potrzebujemy pełnego odtworzenia, aby zachować integralność przekazu.
Transdoc z FineReader
Konfiguracja FineReadera
Na początek należy upewnić się, że FineReader jest zainstalowany i aktualny. W ustawieniach FineReader, w menu „Narzędzia->Opcje”, znajduje się szereg opcji wymagających zmian. Kluczowe jest ustawienie preferencji językowych. Jeśli praca dotyczy dokumentu w języku polskim, należy wybrać właśnie ten język. Nie jest to jedynie sugestia, ale krytyczna konieczność – im dokładniejsze ustawienia językowe, tym lepsza będzie rozpoznawalność tekstu przez FineReader. Można wybrać kilka języków, ale nie warto z tym przesadzać – za duża ilość języków wpłynie negatywnie na prawidłowość rozpoznawania liter i słów.
Przykładowe ustawienia:
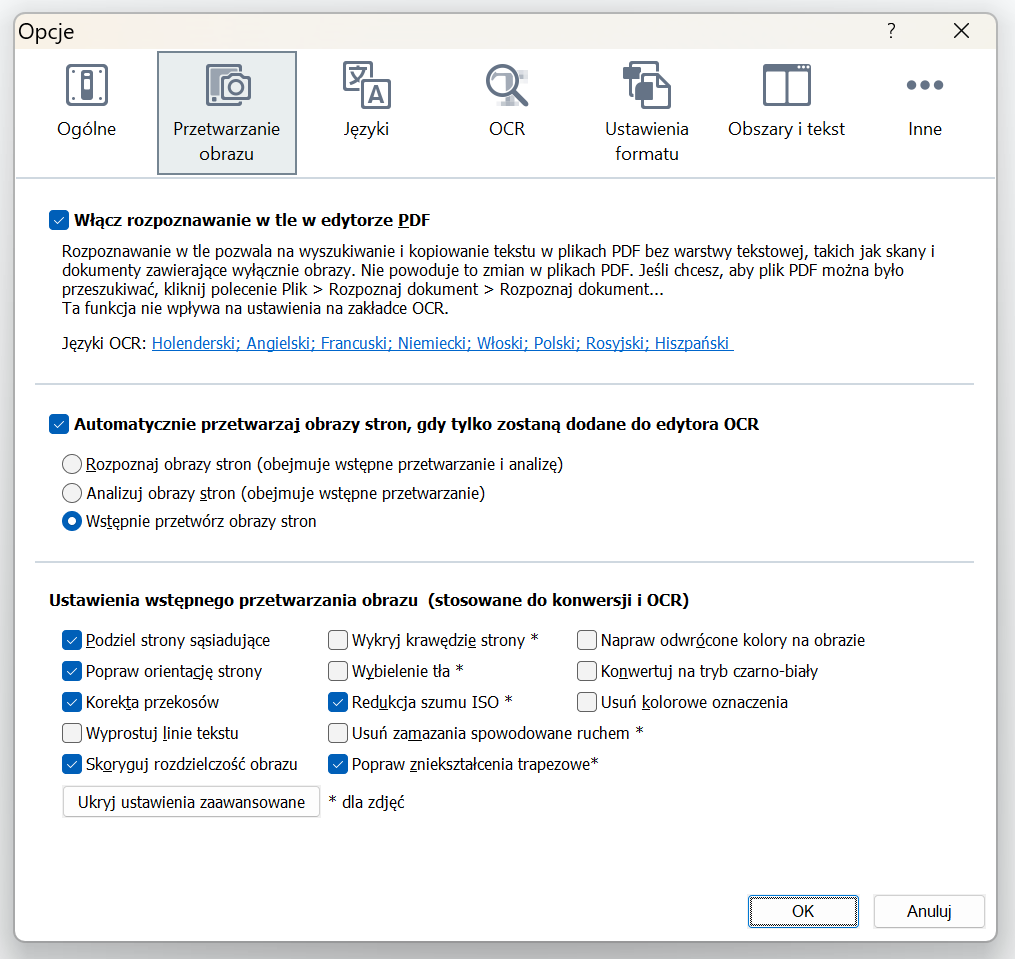
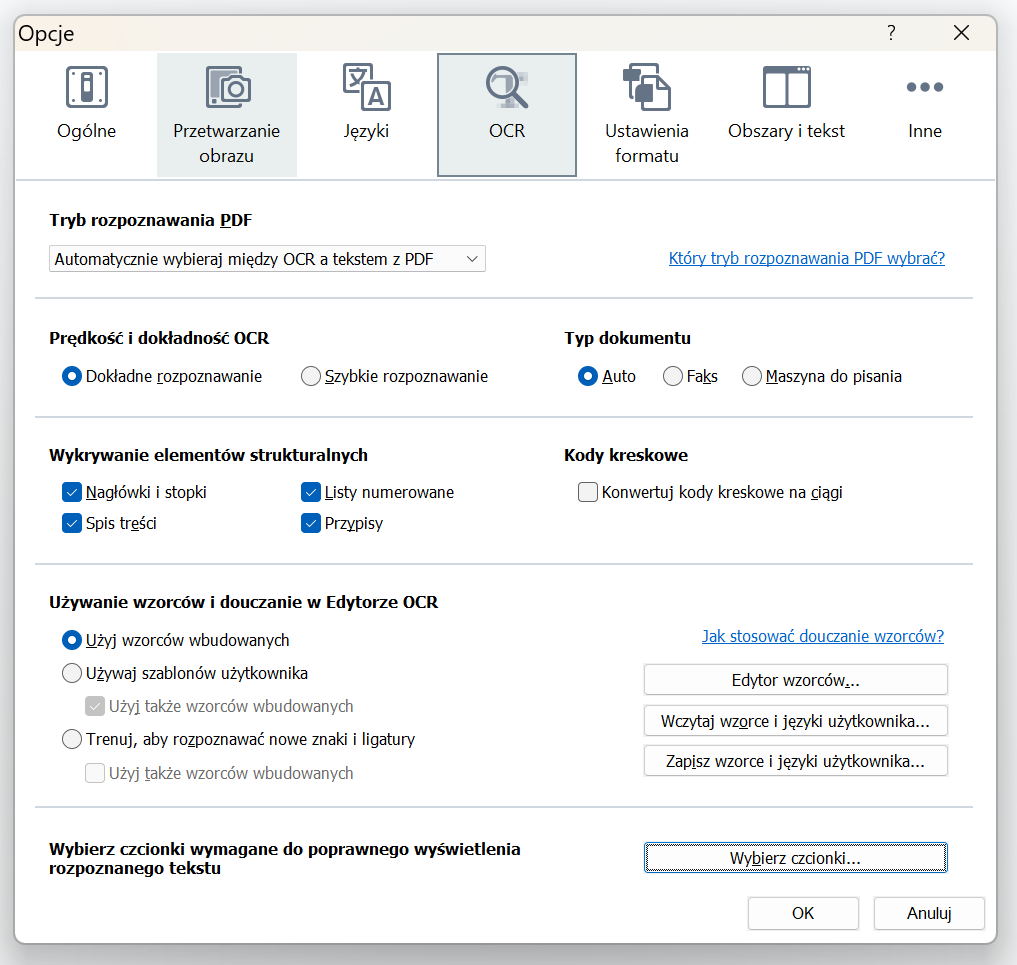
Jeśli nie znasz języka dokumentu, to rozważ włączenie opcji „Zaznacz niepewne znaki” (tylko jeśli nie jest to, co druga litera w zdaniu). Będzie to bodźcem dla tłumacza, by rzucił okiem na oryginalny plik, upewniając się, że OCR jest prawidłowy. Oczywiście zatwierdzamy opcje przyciskiem „OK”.
Kolejnym krokiem jest import nieedytowalnego pliku do Edytora, wstępne rozpoznanie obszarów, poprawienie obszarów, rozpoznanie ich zawartości, poprawienie literówek oraz eksport do DOCX. W Wordzie mamy dwie opcje:
- Posprzątać błędne formatowania po eksporcie, by umożliwić konwersję tekstu na tabelę, wskutek czego wystarczy ją powielić, lewą ukryć i Transdoc gotowy.
- Stworzyć tabelę od początku, po kolei wkleić wyeksportowane teksty do lewej kolumny tej tabeli, a potem ją powielić i lewą ukryć.
Domyślnym skrótem na ukrywanie/odkrywanie treści w MS Word jest CTRL+SHIFT+H.
Rozwiązywanie problemów jest nieuniknioną częścią pracy z technologią. Jedną z najczęstszych przeszkód staje się sytuacja, gdy FineReader nie rozpoznaje określonych czcionek lub stylów w dokumencie. W przypadku Transdoc nie ma znaczenia odwzorowanie fontów, ale ich rozpoznawanie, to już inna sprawa. Jest to zaawansowana funkcjonalność, ale podpowiadamy, że z pomocą przyjdzie Douczanie wzorców (w „Narzędzia->Opcje->OCR”). Rozwiąże to także problem notorycznie błędnie rozpoznawanych konkretnych znaków w dokumencie.
Zaawansowane techniki Transdoc
Dla poszukiwaczy przygód funkcja przetwarzania wsadowego „Hot folder” oferująca możliwość jednoczesnego przetwarzania wielu dokumentów. Funkcja ta pozwala na przetworzenie kilku plików i otrzymanie ich wszystkich gotowych, co znacznie oszczędza czas. Funkcja ta dostępna jest w wyższych wersjach licencji FineReader.
Innym przydatnym narzędziem jest tworzenie własnego języka:
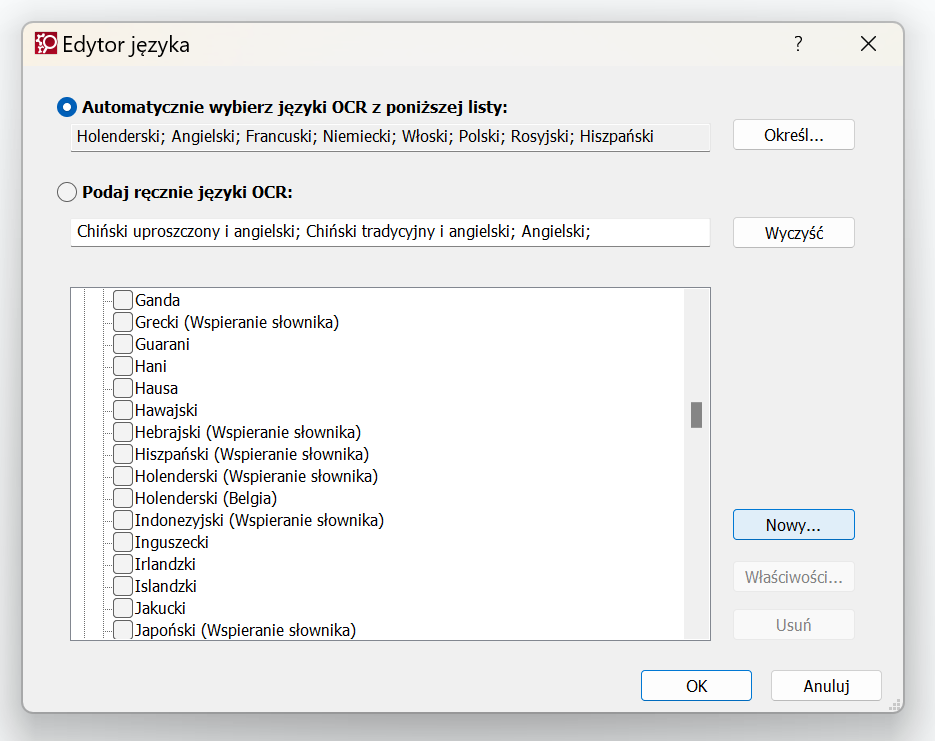
Po kliknięciu „Nowy” wybieramy język bazowy, na podstawie którego tworzymy wariant, a potem możemy wybrać litery alfabetu:
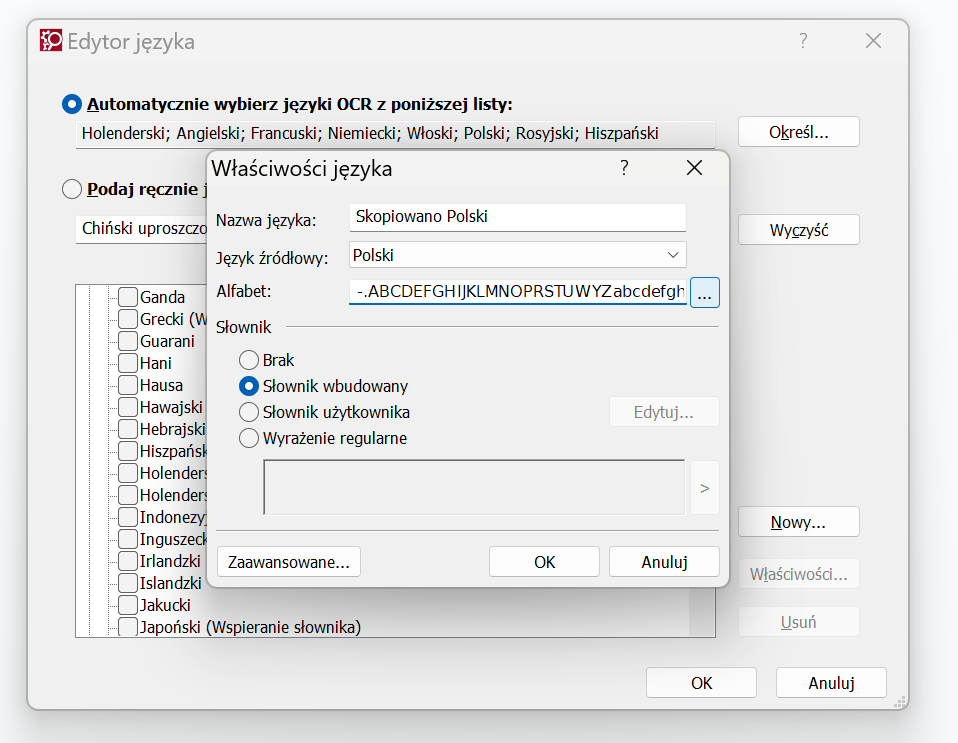
Dzięki temu – w końcu – zaczną rozpoznawać się prawidłowo znaki, które nie chciały rozpoznawać się wcześniej. Oczywiście chodzi o znaki, których nie było domyślnie w danym języku wbudowanym w FineReader. Na przykład, jeśli mamy znaki typu symbole: delta (w sumie całą gamę greckich symboli), średnica, ułamki itp., to one nie będą prawidłowo rozpoznanie, używając domyślnych ustawień. Po kliknięciu „Zaawansowane” mamy jeszcze większą kontrolę nad znakami przypisanymi do danego języka. Język polski domyślnie rozpoznaje następujące znaki:
!”#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]_abcdefghijklmnopqrstuvwxyz{|}~£¥§©«¬®°±»ÓóĄąĆćĘꣳŃńŚśŹźŻż—‘’‛“”„•′€™■□▲△►▻▼▽◄◅◊◎◦★☆♦✓❖
Draft_OCR – proste odwzorowanie
Przed rozpoczęciem OCR konieczne jest odpowiednie przygotowanie dokumentu. Starannie przygotowany materiał źródłowy znacząco zwiększa skuteczność nawet najbardziej zaawansowanego oprogramowania OCR.
Należy upewnić się, że dokument jest zeskanowany w rozdzielczości co najmniej 300 DPI (punktów na cal). Niższe rozdzielczości mogą skutkować rozmytym tekstem, utrudniającym pracę oprogramowania OCR i prowadzącym do niespójnych rezultatów. Istotne jest również usunięcie wszelkich zbędnych elementów, takich jak zagniecenia, znaki wodne, ziarno w tle czy ślady długopisu, które mogłyby zakłócić proces rozpoznawania. Nieraz potrzebny będzie program graficzny np. Photoshop, a innym razem wystarczy np. usunąć znak wodny lub zbędną (drugą) numerację wybierając odpowiednie opcje w edytorze PDF (Acrobat, PDF-XChange Editor itp.).
W FineReaderze zastosowanie mają takie same ustawienia jak wcześniej, ale z jednym wyjątkiem:
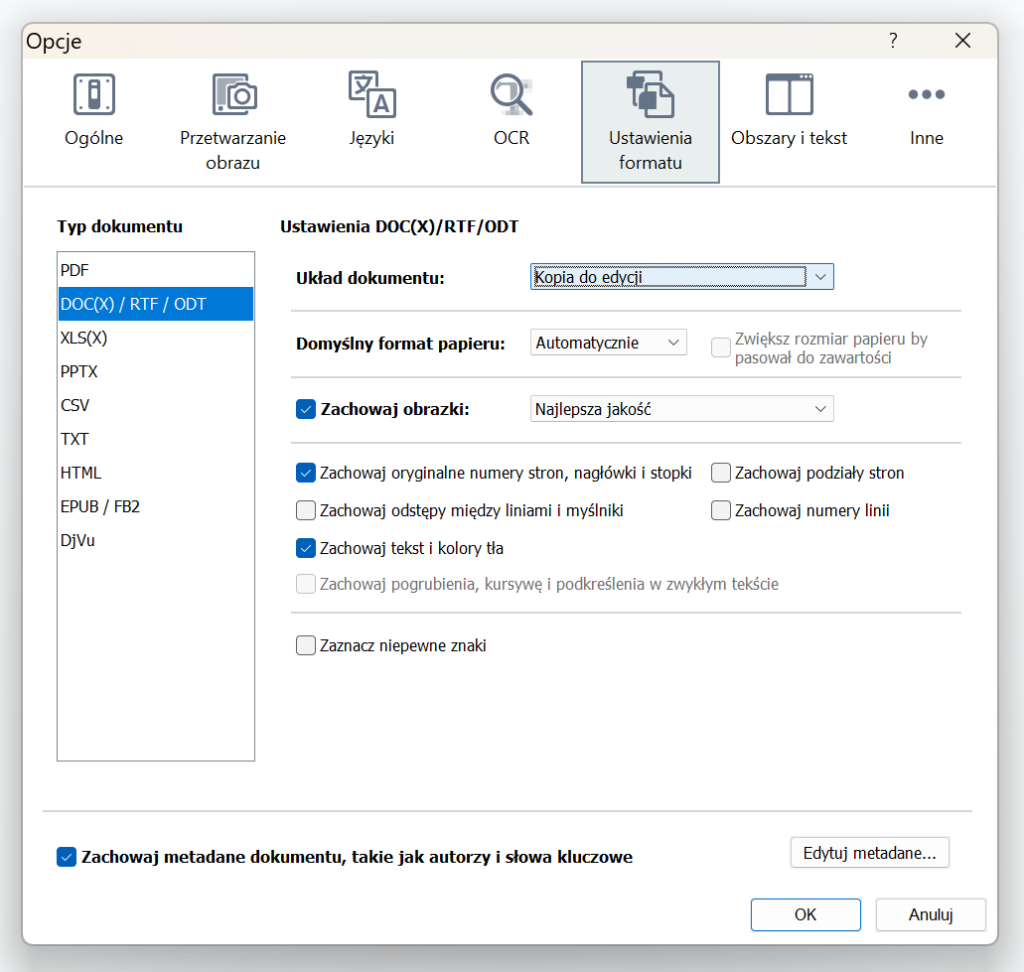
Włączamy zachowanie numerów stron, nagłówków i stopek oraz możemy pokusić się o zmianę układu dokumentu na „Kopia do edycji”. Nie zawsze się to sprawdzi, a raczej wyłącznie w przypadku prostszych układów. Wybierając tę opcję, nic nie tracimy. W razie potrzeby można to zmienić później – bez dodatkowej pracy.
Konwersja do DOCX
Praca z FineReaderem będzie analogiczna, jak wyżej, czyli import nieedytowalnego pliku do Edytora, wstępne rozpoznanie obszarów, poprawienie obszarów, rozpoznanie ich zawartości, poprawienie literówek oraz eksport do DOCX. Jeśli eksport do Worda (gdyż mamy opcję zapisania do DOCX lub wysłania do Worda – można ich używać zamiennie – efekt pracy FineReadera jest taki sam) posiada masę ramek tekstowych lub pól, to oczywiście należy zmienić układ na tekst sformatowany i spróbować ponownie.
Podstawowe formatowanie
Po uzyskaniu edytowalnego tekstu przychodzi czas na jego dopracowanie. Podstawowe formatowanie to etap, na którym możemy tchnąć życie w nasz draft_OCR.
Jak pisaliśmy na początku: w tym przypadku odwzorowuje się oryginalne teksty z zachowaniem logicznego porządku oraz niezbędnych przepływów wraz z formatowaniem lokalnym takim, jak pogrubienia, podkreślenia, indeksy, pismo kursywne (i inne oczywiste wyróżnienia wewnątrz zdania, które mają zastosowanie funkcjonalne).
Na taką okoliczność warto stworzyć sobie arkusz styli, który zawsze importujemy do pliku po OCR i formatujemy nim cały dokument, osiągając, w ten sposób, spójny, czysty i przejrzysty plik przygotowany do tłumaczenia.
W przypadku dokumentów wielojęzycznych należy upewnić się, że języki, które nie będą źródłowym (dla tłumacza), zostaną ukryte na czas tłumaczenia lub zignorowane na etapie przygotowywania OCR.
Bardzo ważne jest, aby usuwać zbędne podziały tzn. twarde entery, bo wpłyną one na segmentację pliku w narzędziu CAT, a tam, gdzie podział jest niezbędny, to zastąpienie twardego entera miękkim. Jeśli jakieś zdania są podzielone twardymi enterami (np. Między stronami), to takie zdania trzeba połączyć w logiczną całość.
Kontrola jakości
Po ukończeniu draft_OCR należy uważnie przeczytać tekst, poszukując typowych błędów związanych z OCR, takich jak błędnie rozpoznane znaki czy nieprawidłowa interpunkcja. Chociaż narzędzia programowe mogą przyspieszyć ten proces, ludzkie oko pozostaje niezastąpione w wykrywaniu subtelnych nieprawidłowości. Stosunkowo niewielu użytkowników FineReadera korzysta z modułu kontroli pisowni wbudowanego w ten program. Rekomenduje się korzystanie z tej funkcjonalności – po to jest – ale, w ostateczności, można ten proces odroczyć i wykonać kontrolę pisowni (F7) w MS Word. Jest to etap, który prędzej, czy później będzie trzeba wykonać.
Wskazówki
W przypadku szczególnie wymagających dokumentów (np. dokumentów liczących setki stron) warto rozważyć podzielenie ich na mniejsze sekcje. Umożliwi to bardziej skoncentrowane rozpoznawanie OCR.
Jeśli podziały stron są istotne, zaleca się użycie podziałów w stylach akapitowych w Wordzie zamiast ręcznych podziałów sekcji.
Nie należy bagatelizować wartości ręcznych poprawek. OCR, choć zaawansowane, nie jest nieomylne. Przygotowanie się na ręczne usuwanie pozostałych niedoskonałości stanowi część profesjonalnego podejścia do procesu.
Pełne odwzorowanie graficzne
Każdy element przygotowań może zadecydować o sukcesie lub porażce. Poświęcenie czasu na eksplorację i zrozumienie ustawień – od podstawowych opcji rozpoznawania języka po zaawansowane narzędzia formatowania (np. wybór fontów*) – przynosi korzyści. Dostosowanie paska narzędzi zwiększa efektywność pracy.
Jakość skanów stanowi fundament udanego OCR. Stosowanie rozdzielczości minimum 300 DPI dla dokumentów tekstowych jest zalecane. Oczywiście nie ma to znaczenia, jeśli pracujemy z plikiem PDF, który skanem nie jest. W przypadku skomplikowanych układów pomocna okazuje się funkcja automatycznego wykrywania struktury dokumentu.
*możemy wybierać spośród fontów zainstalowanych w systemie. Dzięki temu będą użyte już w eksporcie do DOCX.
Lokalizacja grafik
Podstawowe opcje są dwie:
- Nanoszenie pól tekstowych na grafiki zawierające tekst do tłumaczenia.
- Tworzenie mini-transdoc, czyli tabelki-legendy pod grafiką, która wymaga tłumaczenia.
Obydwa warianty wymagają OCR i przygotowania, a o jego wyborze powinien zadecydować klient końcowy lub zleceniodawca.
Alternatywnie można wyeksportować wszystkie grafiki z PDF lub wykonując OCR nie zaznaczać tekstów na grafikach, wyciągając je (grafiki) w niezmienionej formie, aby później rozpakować DOCX (wystarczy zmienić rozszerzenie z DOCX na ZIP) i w podkatalogu word/media znaleźć wszystkie grafiki użyte w dokumencie, w celu ich lokalizacji poza Wordem (np. w Photoshopie).
Optymalizacja pod kątem CAT
OCR dla narzędzi CAT zwiększa efektywność pracy tłumaczy. FineReader pozwala eksportować wyniki do formatów kompatybilnych z systemami CAT. Niestety zdarza się, że eksport posiada zbędne style, „śmieciowe” formatowanie i inne elementy, które przeszkadzają tłumaczowi w pracy, generując zbędne tagi. Wskazane jest, by grafik przygotowujący plik do pracy w CAT posiadał np. Tradosa i mógł podejrzeć, jak wygląda OCR, zanim prześle go dalej. Dzięki temu widać problemy wymagające wyeliminowania przed przekazaniem pliku do kolejnego etapu produkcji. W internecie znajdziemy kilka makr lub skryptów do Worda, które eliminują spore ilości zbędnych tagów np. Codezapper. Należy jednak pamiętać, że każdy tak coś oznacza – usuwając tag, usuwamy coś więcej. Bez możliwości podglądu OCR przed i po usunięciu tagów jest ryzykowne i może się opłacić, ale nie musi. 50 na 50. Zastosowanie mają te same zasady, co wyżej, czyli optymalizacja twardych i miękkich enterów, łączenie podzielonych tekstów, dzielenie tekstów, które powinny być oddzielone, a brakuje podziałów, automatyczne numeracje zamiast ręcznych itd.
Wskazówki
MS Word ma limit wielkości strony – 55,88 cm x 55,88 cm – więc dokumenty o większym formacie, mogą wymagać przeskalowania (zmniejszenia).
Standardowo unika się używania pól tekstowych w OCR, ale schematy elektryczne, rysunki techniczne oraz projekty mogą wymagać użycia pól tekstowych.
Pola tekstowe muszą być właściwie i rozważnie kotwiczone do innych elementów np. akapitu lub strony. W przeciwnym razie, wskutek zmiany długości tekstu (w tłumaczeniu), zmienią swoje położenie. Ma to zastosowanie również do innych elementów graficznych, które występują w plikach o pełnym odwzorowaniu.
Razem z FineReaderem otrzymujemy również Screenshot Reader, który przydaje się do szybkiego, punktowego wyciągania pojedynczych tekstów np. na potrzeby tworzenia legend pod grafikami wymagającymi lokalizacji.
Zdarzają się problemy z ponownym otwarciem wiązki (zapisanego projektu FineReadera), więc rekomenduje się zakończenie prac nad otwartym dokumentem bez zamykania i ponownego otwierania FineReadera.
W ustawieniach formatu możemy wybrać niestandardowe ustawienia zapisywanych grafik, by wybrać między innymi stopień ich kompresji (Jakość):
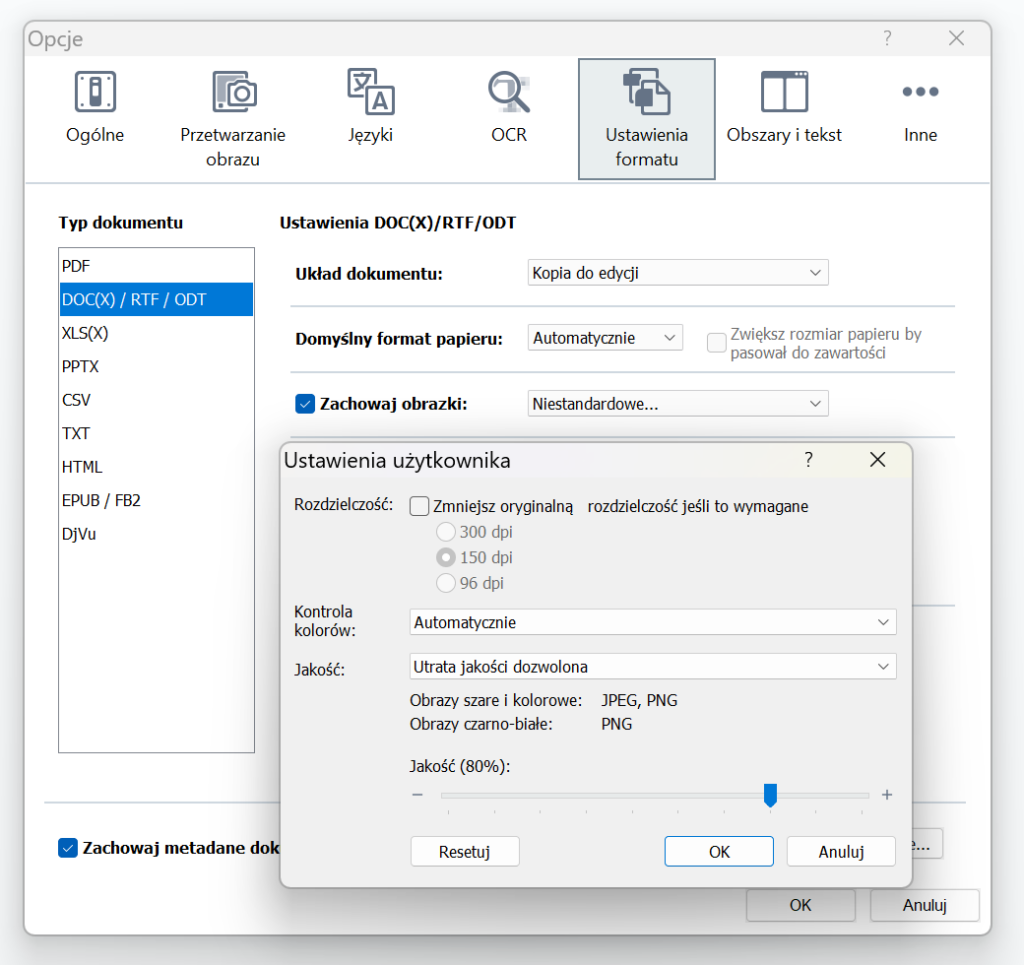
Może się to przydać w przypadku dokumentów o dużej ilości grafik oraz stron, by uniknąć Worda „ważącego” kilkaset MB.
Korzyści płynące z doskonałego OCR
Dokładność stanowi fundament każdego udanego projektu tłumaczeniowego – cecha nadająca słowom znaczenie. Perspektywa odszyfrowywania nieczytelnej strony lub czytania tłumaczenia pełnego błędów nie jest atrakcyjna dla nikogo. Wzrost dokładności przekłada się na większe zadowolenie klientów. Efektywny proces OCR może znacząco skrócić czas realizacji projektu. Tłumacze, którzy umiejętnie wykorzystują zaawansowane techniki OCR, są w stanie osiągnąć imponującą wydajność bez kompromisów w zakresie jakości, przy okazji zyskując dodatkową przewagę konkurencyjną.
Korzyści z efektywnego OCR wykraczają poza indywidualnych tłumaczy czy klientów, wpływając pozytywnie na całą branżę. Wyższa jakość prowadzi do mniejszej liczby korekt i poprawek, przyspieszając harmonogramy projektów i umożliwiając podejmowanie nowych zadań. Firmy o usprawnionej organizacji pracy są lepiej przygotowane do efektywnego rozwiązywania problemów, co przekłada się na ich konkurencyjność na rynku.
Idea jest prosta: bezbłędne przygotowanie procesów OCR poprawia każdy aspekt pracy tłumaczeniowej. Prawidłowo sformatowane dokumenty, bezbłędne teksty i bezproblemowa integracja oznaczają mniejszą presję na wszystkie zaangażowane strony, tworząc środowisko sprzyjające innowacjom i współpracy. Osiągnięcie tego poziomu jakości wymaga staranności i przemyślenia, ale efekty są warte wysiłku.
Najlepsze praktyki OCR
- Zanim rozpocznie się OCR, należy odpowiednio przygotować dokument. Zły stan dokumentu może nie tylko utrudnić pracę oprogramowania, ale także doprowadzić do frustracji podczas dalszej obróbki.
- Oceń jakość dokumentu źródłowego. Jeśli jest w złym stanie, zajmij się jego poprawą lub poproś o lepszą kopię. Upewnij się, że strony są płaskie, czyste i pozbawione zagnieceń czy plam. Podczas digitalizacji dokumentu papierowego, użyj skanera z minimalną rozdzielczością 300 DPI, aby uzyskać optymalną ostrość.
- Nadaj dokumentowi logiczną strukturę, jeśli jej brakuje. Ponumeruj strony, dodaj nagłówki i usuń wszelkie niepotrzebne elementy. Spójne przedstawienie dokumentu znacząco ułatwia pracę oprogramowania OCR.
- Każde oprogramowanie OCR ma swoje unikalne mocne i słabe strony. Kluczowe jest przeanalizowanie konkretnych potrzeb projektu. Narzędzia takie jak ABBYY FineReader doskonale radzą sobie z formatowaniem całych stron i interpretacją tabel – idealne do tłumaczenia obszernych raportów. Z kolei prostsze aplikacje mogą zapewnić szybkie wyniki, ale brakuje im precyzji w przypadku złożonych układów tekstu lub wielu języków.
- Korekta OCR wymaga precyzji i cierpliwości. OCR nieuchronnie popełnia błędy; niektóre litery lub liczby mogą zostać nieprawidłowo rozpoznane, a interpunkcja może wymagać korekty.
- Najlepszą praktyką jest porównywanie oryginalnego dokumentu z wynikiem OCR, strona po stronie. Może to wydawać się żmudne, ale zaniedbanie tego etapu może skutkować kosztownymi błędami, szczególnie w przypadku dokumentów technicznych lub prawnych.
Optymalizacja plików DOCX dla narzędzi CAT
Znajomość specyficznych wymagań wybranego narzędzia CAT jest fundamentem skutecznej optymalizacji. Każde oprogramowanie ma swoje unikalne cechy i ograniczenia, które należy uwzględnić.
Większość narzędzi CAT radzi sobie dobrze z plikami DOCX, jednak kluczowe jest zrozumienie ich specyfiki. Niektóre mogą mieć trudności z zaawansowanym formatowaniem lub osadzonymi obiektami. Warto dokładnie zapoznać się z dokumentacją techniczną oprogramowania, aby zidentyfikować jego możliwości i ograniczenia.
Szczególną uwagę należy zwrócić na zachowanie stylów, nagłówków, stopek i osadzonych obrazów po przetworzeniu przez narzędzie CAT. Dokładne zrozumienie tych aspektów pozwoli uniknąć nieprzyjemnych niespodzianek w trakcie procesu tłumaczenia.
Ustawienia segmentacji
Właściwe ustawienia segmentacji są kluczowe dla płynności procesu tłumaczenia. Umożliwiają one wyraźne oddzielenie segmentów tekstu, które narzędzie CAT będzie przetwarzać w formie jednostek tłumaczeniowych w celu zapisania w bazie tłumaczeniowej.
Większość narzędzi CAT oferuje domyślne reguły segmentacji, które można dostosować do struktury konkretnego dokumentu. Warto rozważyć modyfikację ustawień segmentacji w zależności od typu dokumentu i jego specyfiki. No tak, ale miało być o dostosowywaniu plików DOCX do CAT, a nie odwrotnie. Zgadza się! Aby tak zrobić, najpierw trzeba zrozumieć, jakie są te domyślne reguły segmentacji, aby grafik mógł przygotować plik, zachowując zgodność z tymi regułami. Na przykładzie Tradosa (kluczowe zasady dzielenia segmentów dla plików DOCX):
- Kropki: segmentacja na końcu zdania, kiedy kropka jest zakończona białym znakiem, np. „To jest zdanie. To jest kolejne zdanie”.
- Wykrzykniki: segmentacja po wykrzykniku, np. „Uwaga! To jest ważne”.
- Znaki zapytania: segmentacja po znaku zapytania, np. „Czy to działa? Tak, działa”.
- Średniki: średniki mogą, ale nie muszą, inicjować dzielenia, w zależności od ustawień, np. „To jest przykład; to również jest przykład”.
- Podziały akapitów: każdy nowy akapit zazwyczaj zaczyna nowy segment.
- Cudzysłowy i nawiasy: tekst zamknięty w cudzysłowach lub nawiasach jest traktowany jako część bieżącego segmentu, chyba że kończy się kropką, wykrzyknikiem lub znakiem zapytania.
Tagi
Odpowiednie tagowanie pliku DOCX zwiększa przejrzystość i zapewnia płynniejszy proces tłumaczenia. Tagi działają jak drogowskazy, prowadząc tłumacza przez dokument i zabezpieczając formatowanie treści.
Wiele narzędzi CAT wykorzystuje tagi do identyfikacji elementów wewnątrz linii, takich jak pogrubienia, kursywa czy hiperłącza. Istotne jest, aby tagi były prawidłowo umieszczone i sformatowane. Przygotowując plik DOCX, należy upewnić się, że tagi odpowiadają zamierzonemu formatowaniu. Na przykład, jeśli fraza w tekście źródłowym jest pogrubiona, odpowiedni tag w DOCX powinien to odzwierciedlać, aby zachować takie samo wyróżnienie w tłumaczeniu. Zbędne taki potrafią katastrofalnie wpłynąć na wydajność tłumacza, a reperkusje przekroczonych terminów mogą być dotkliwe.
Przykład zbędnych tagów (źródło: community.rws.com):
Przygotowanie glosariuszy i pamięci tłumaczeniowych
OCR można również wykorzystać do stworzenia wielojęzycznego glosariusza lub bazy pamięci tłumaczeniowej (z wcześniej wykonanych tłumaczeń). Dzięki OCR możliwe jest szybkie i efektywne wyodrębnienie tekstu z wcześniej przetłumaczonych dokumentów, co pozwala na ich dalsze wykorzystanie. Przykładowo można stworzyć glosariusz z 8-języcznej deklaracji zgodności lub 4-języcznego katalogu części w celu spójnego tłumaczenia tych samych fraz w przyszłości. Jeśli chodzi o bazy tłumaczeniowe, to może się zdarzyć, że klient będzie zmieniał biuro tłumaczeń. Od poprzedniego biura nie dostanie swoich baz tłumaczeniowych, a wie, że w jego tekstach jest dużo powtórzeń, za które wolałby nie płacić ponownie, co jest oczywiste. W takim wypadku może dostarczyć „stare” PDFy – źródłowe oraz przetłumaczone – z których wykonuje się OCR, a potem bazę tłumaczeniową, która jest wykorzystywana do podnoszenia jakości oraz redukcji kosztów we współpracy z nowym biurem tłumaczeń.
QA przed importem do narzędzia CAT
Wykonywanie końcowej kontroli przed importem pliku DOCX po OCR do narzędzia CAT jest kluczowe. Etap ten można porównać do próby generalnej przed występem – upewniamy się, że wszystkie elementy są na swoim miejscu i gotowe do działania.
Należy zwrócić szczególną uwagę na:
- niechciane, często wielokrotne spacje,
- niespójności w typografii (różne rozmiary lub style fontów),
- nadgorliwe podziały wierszy,
- literówki i błędy OCR,
- pominięte/nieprzygotowane elementy graficzne.
Przeprowadzenie dokładnego sprawdzenia dokumentu nie tylko zwiększy pewność co do jego należytej jakości, ale może również ujawnić obszary wymagające dalszych korekt.
Pamiętaj, że niektóre problemy można rozwiązać dużo szybciej i efektywniej na wczesnym etapie, a później będzie tylko gorzej. Błędy w dokumencie tłumaczonym docelowo na 27 języków będzie trzeba poprawić 27 razy w przetłumaczonych plikach!
Kluczowe wnioski
Dla profesjonalistów w dziedzinie tłumaczeń i projektowania graficznego kluczowe jest przyjęcie strategicznego podejścia do rozwiązań OCR. Umiejętność krytycznej oceny i efektywnego wykorzystywania narzędzi OCR oraz AI staje się niezbędna. Współpraca z dostawcami usług OCR może prowadzić do rozwoju bardziej zaawansowanych i dostosowanych narzędzi. Aktywny udział w kształtowaniu tych technologii pozwoli na lepsze dostosowanie ich do potrzeb branży.
Przyszłość OCR oferuje ekscytujące możliwości dla tłumaczy i grafików. Aktywne zaangażowanie w rozwój tych technologii pozwoli na wykorzystanie ich potencjału przy jednoczesnym zachowaniu wysokich standardów jakości i kreatywności w pracy.
Kontakt

Ukryte koszty tanich tłumaczeń AI: na co uważać?
Tłumaczenia AI stają się coraz bardziej popularne w środowisku biznesowym. Niskie koszty oraz szybka i łatwa dostępność sprawiają, że są one atrakcyjną opcją dla wielu przedsiębiorstw. Niemniej jednak warto zastanowić się nad ukrytymi kosztami tanich rozwiązań oraz zrozumieć ryzyko związane z ich stosowaniem.
Dlaczego temat tanich tłumaczeń AI jest tak ważny dla biznesu?
Decyzje dotyczące wyboru metod tłumaczenia mogą znacząco wpłynąć na funkcjonowanie i sukces przedsiębiorstwa. Tanie tłumaczenia AI oferują możliwość szybkiego przekładu dużej ilości treści przy minimalnych kosztach. Jednakże niska cena często idzie w parze z kompromisami dotyczącymi jakości i dokładności tłumaczeń.
Firmy działające na rynkach międzynarodowych muszą komunikować się precyzyjnie i bez błędów językowych, aby uniknąć nieporozumień mogących prowadzić do strat finansowych lub wizerunkowych. Przykładem może być sytuacja, w której błędnie przetłumaczony dokument umowy prowadzi do niezrozumienia warunków współpracy i finalnie do konfliktu prawnego.
Wpływ wyboru metody tłumaczenia na jakość przekazu i bezpieczeństwo informacji
Metoda tłumaczenia ma bezpośredni wpływ na jakość przekazu oraz bezpieczeństwo informacji w firmie. Tłumaczenia AI, które bazują na zaawansowanych algorytmach i modelach językowych, mogą być wystarczające dla prostych tekstów o niskim stopniu specjalizacji. Jednak w przypadku bardziej skomplikowanych dokumentów technicznych, prawniczych czy medycznych, obecność ludzkiego tłumacza jest nieodzowna.
Jakość przekazu
- Brak kontekstu: algorytmy AI często mają trudności ze zrozumieniem kontekstu kulturowego, idiomatycznego czy branżowego, co prowadzi do przetłumaczenia treści w sposób dosłowny lub nieadekwatny.
- Błędy terminologiczne: brak precyzyjnej terminologii specjalistycznej może skutkować błędami merytorycznymi w przetłumaczonych tekstach.
Bezpieczeństwo informacji
- Ryzyko wycieku danych: korzystanie z publicznie dostępnych narzędzi AI niesie ze sobą ryzyko wycieku poufnych informacji. Przesyłanie dokumentów przez niezabezpieczone kanały może prowadzić do ich przechwycenia przez osoby trzecie.
- Niezgodność z przepisami RODO: wiele ogólnodostępnych narzędzi AI przetwarza dane użytkowników poza granicami Unii Europejskiej, co może naruszać przepisy o ochronie danych osobowych (RODO).
Ograniczenia i ryzyko korzystania z publicznie dostępnych narzędzi do tłumaczeń AI
Algorytmy sztucznej inteligencji, mimo zaawansowania technologicznego, często mają trudności z interpretacją skomplikowanych kontekstów językowych. Przykładowo:
Fraza „We need to address the elephant in the room” może zostać przetłumaczona dosłownie jako „Musimy porozmawiać o słoniu w pokoju”, co całkowicie zmienia znaczenie oryginalnej wypowiedzi, która odnosi się do konieczności omówienia trudnego tematu.
Brak kontekstu prowadzi nie tylko do niewłaściwego przekazu informacji, ale także może wywoływać nieporozumienia lub błędy komunikacyjne, wpływając negatywnie na relacje biznesowe.
Brak niuansów kulturowych
Tłumaczenie bez uwzględnienia niuansów kulturowych to kolejna pułapka narzędzi opartych wyłącznie na AI. Każdy język niesie ze sobą specyficzne dla danej kultury idiomy, metafory oraz konotacje, które mogą być trudne do uchwycenia przez AI. Na przykład:
- Angielskie idiomy takie jak „kick the bucket” (dosłownie: kopnąć wiadro) oznaczające śmierć (odpowiednik: „kopnąć w kalendarz”), mogą być przetłumaczone dosłownie na inne języki, co skutkuje niezrozumiałym przekazem.
- Polskie wyrażenia jak „mieć muchy w nosie” (być obrażonym) mogą nie mieć analogicznych odpowiedników w innych językach, co utrudnia precyzyjne tłumaczenie.
Ryzyko prawne
Ryzyko prawne to kolejny istotny aspekt korzystania z ogólnodostępnych narzędzi do tłumaczeń AI. Wiele dokumentów biznesowych zawiera klauzule prawne, które muszą być precyzyjnie przetłumaczone. Błędy w tłumaczeniu takich dokumentów mogą prowadzić do poważnych konsekwencji prawnych. Na przykład:
- Umowy wymagają dokładnej interpretacji terminologii prawniczej; błędy w tłumaczeniu mogą skutkować utratą ważności umowy lub niewłaściwym jej wykonaniem.
- Regulacje rynkowe i normy branżowe często są specyficzne dla danego kraju i wymagają dokładnego odwzorowania w tłumaczeniu.
Korzystanie z narzędzi AI może prowadzić do sytuacji, w których firma będzie narażona na sankcje prawne lub finansowe.
Ryzyko ekonomiczne
Równie istotne jest ryzyko ekonomiczne wynikające z polegania wyłącznie na publicznych narzędziach AI. Niewłaściwe tłumaczenia mogą wpłynąć na reputację firmy oraz prowadzić do strat finansowych. Przykłady obejmują:
- Błędy w materiałach marketingowych, które mogą wywołać niezrozumienie oferty przez klientów. Na przykład, źle przetłumaczone hasła reklamowe mogą nie oddawać właściwego przekazu, co skutkuje zmniejszeniem zainteresowania produktami lub usługami.
- Niewłaściwe tłumaczenia dokumentacji technicznej mogą prowadzić do problemów z użytkowaniem produktów przez klientów. Może to skutkować większą liczbą reklamacji – a nawet szkodami osobowymi – i potrzebą dodatkowego wsparcia technicznego, co generuje dodatkowe koszty.
- Błędne tłumaczenie ofert handlowych może wpłynąć na negocjacje i finalizowanie transakcji. Nieprecyzyjne sformułowania w umowach handlowych mogą prowadzić do nieporozumień i potencjalnych sporów prawnych.
- Problemy z lokalizacją strony internetowej – nieodpowiednie tłumaczenia treści online mogą wpływać na doświadczenie użytkowników i obniżać konwersje sprzedażowe.
- Inwestycja w profesjonalne usługi tłumaczeniowe pozwala uniknąć tych problemów, zapewniając, że wszystkie materiały są precyzyjnie przetłumaczone i zgodne z lokalnymi normami oraz oczekiwaniami kulturowymi.
Dlaczego warto inwestować w bezpieczne rozwiązania AI oferowane przez profesjonalne biura tłumaczeń?
Zalety wykorzystania zaawansowanych technologicznie, ale bezpiecznych rozwiązań AI przez doświadczone biura tłumaczeń
Profesjonalne biura tłumaczeń nie tylko korzystają z zaawansowanych narzędzi AI, ale również integrują je w sposób, który zapewnia wysoki poziom bezpieczeństwa i jakości. W przeciwieństwie do ogólnodostępnych narzędzi, rozwiązania stosowane przez profesjonalistów są dopasowane do specyficznych potrzeb klienta oraz branży.
Zalety inwestycji w profesjonalne rozwiązania AI:
- Bezpieczeństwo danych: profesjonalne biura tłumaczeń korzystają z zaawansowanych protokołów bezpieczeństwa, które chronią poufne informacje przed nieautoryzowanym dostępem.
- Głębokie zrozumienie kontekstu: dzięki połączeniu technologii i ludzkiej inteligencji, tłumaczenia uwzględniają specyficzny kontekst kulturowy i branżowy.
- Kreatywność i adaptacja: narzędzia stosowane przez specjalistów pozwalają na elastyczne dostosowanie stylu i tonu przekazu, co jest kluczowe w takich dziedzinach jak marketing czy reklama.
- Dokładność: zaawansowane silniki AI wspierane przez ludzkich ekspertów minimalizują ryzyko błędów językowych i merytorycznych.
Jak ludzkie doświadczenie i kompetencje dziedzinowe przekładają się na jakość tłumaczeń?
Doświadczone biura tłumaczeń łączą moc technologii AI z wiedzą specjalistyczną swoich pracowników, co znacząco wpływa na jakość końcowego produktu.
Korzyści wynikające z ludzkiego doświadczenia:
- Doświadczenie branżowe: specjaliści w dziedzinach takich jak finanse czy prawo mają dogłębną znajomość terminologii i przepisów, co jest kluczowe dla precyzyjnych tłumaczeń tego typu.
- Adaptacja do specyfiki językowej: tłumacze mogą dostosować tłumaczenie do lokalnych dialektów i idiomatyk, co jest szczególnie ważne w komunikacji biznesowej.
- Krytyczne myślenie i kreatywność: ludzie potrafią rozpoznać niuanse językowe oraz kontekstualne, które są kluczowe dla skutecznej komunikacji międzykulturowej.
Przykłady zastosowania:
W branży finansowej dokładność terminologiczna ma kluczowe znaczenie dla uniknięcia kosztownych błędów. Profesjonalne biura tłumaczeń wykorzystują zarówno technologie AI, jak i wiedzę specjalistyczną swoich pracowników do tworzenia precyzyjnych dokumentów finansowych.
W dziedzinie prawa każde słowo może mieć istotne znaczenie prawne. Profesjonalni tłumacze prawniczy korzystający z zaawansowanych narzędzi AI mogą zapewnić, że każdy dokument jest zgodny z wymaganiami prawnymi danego kraju.
Inwestycja w bezpieczne rozwiązania AI
Inwestycja w bezpieczne rozwiązania AI oferowane przez profesjonalne biura tłumaczeń to strategiczny krok, który przynosi liczne korzyści.
Główne zalety inwestowania w rozwiązania AI:
- Automatyzacja procesów: dzięki AI możliwe jest automatyczne tłumaczenie dużych ilości tekstu w krótkim czasie, co przyspiesza realizację projektów.
- Zwiększona dokładność: technologie oparte na AI wspierane przez ludzi oferują najwyższą dokładność.
- Bezpieczeństwo danych: profesjonalne biura tłumaczeń stosują zaawansowane zabezpieczenia, aby chronić poufne informacje klientów.
Przykłady zastosowania:
- Tłumaczenia techniczne: w branży technologicznej precyzja jest kluczowa. AI wspierana przez ekspertów zapewnia zgodność terminologiczną i techniczną.
- Dokumenty medyczne: tłumaczenie dokumentacji medycznej wymaga precyzji i znajomości specyficznych terminów. AI pomaga w szybkim i dokładnym przekładzie.
W erze cyfrowej, gdzie dane są nową walutą, inwestowanie w bezpieczne rozwiązania AI to nie tylko trend, ale konieczność.
Nasza filozofia: połączenie sił człowieka i technologii w tłumaczeniach
Dlaczego wierzymy w znaczenie łączenia sił ludzkich i technologicznych w procesie tłumaczenia?
Kluczowe jest zrozumienie, że sama technologia nie jest wystarczająca do zapewnienia najwyższej jakości tłumaczeń. Nasza filozofia „slow translation” opiera się na przekonaniu, że najlepsze rezultaty osiągane są poprzez harmonijne połączenie zdolności ludzkich oraz zaawansowanych narzędzi AI.
Tłumaczenie to nie tylko mechaniczne przekształcanie słów z jednego języka na inny. Wymaga ono dogłębnego zrozumienia kontekstu kulturowego, intencji autora oraz specyfiki branży. Ludzie mają zdolność interpretacji niuansów językowych, a także wyłapywania w locie błędów w tekście źródłowym (oraz ich poprawiania lub konsultowania), co jest niezbędne do tworzenia tłumaczeń najwyższej jakości. AI może wspierać ten proces, przyspieszając pracę i eliminując błędy typowe dla monotonnych zadań.
Zastosowanie odpowiednich narzędzi AI umożliwia:
- Automatyczne wykrywanie błędów gramatycznych i stylistycznych, co pozwala tłumaczom skupić się na bardziej złożonych aspektach treści.
- Zapewnienie spójności terminologicznej poprzez wykorzystanie baz danych i glosariuszy specyficznych dla danej branży.
- Skrócenie czasu realizacji projektów, co jest szczególnie ważne w przypadku dużych zleceń lub pilnych potrzeb klientów.
Odpowiedzialne podejście do wykorzystywania narzędzi AI w naszej pracy
Wykorzystanie technologii niesie ze sobą także pewne ryzyka, które mogą negatywnie wpłynąć na jakość tłumaczeń oraz bezpieczeństwo danych. Dlatego odpowiedzialność w korzystaniu z narzędzi AI jest fundamentem naszej filozofii pracy.
Filozofia „slow translation”
Nasza filozofia „slow translation” zakłada, że nawet przy użyciu szybkich narzędzi technologicznych najważniejsza jest jakość końcowego produktu. Właśnie dlatego stawiamy na połączenie sił człowieka i technologii w procesie tłumaczenia.
Dlaczego warto zainwestować w usługi świadczone przez profesjonalistów?
Inwestowanie w profesjonalne tłumaczenia przynosi szereg korzyści, które przekładają się na sukces biznesowy:
- Gwarancja jakości: profesjonalni tłumacze mają doświadczenie i wiedzę specjalistyczną, co pozwala im dostarczać tłumaczenia najwyższej jakości, uwzględniając kontekst kulturowy oraz terminologię branżową.
- Indywidualne podejście: każdy projekt jest traktowany indywidualnie, co pozwala na lepsze dopasowanie treści do specyfiki odbiorcy oraz zachowanie spójności stylistycznej.
- Bezpieczeństwo danych: biura tłumaczeń dbają o poufność informacji swoich klientów poprzez stosowanie odpowiednich zabezpieczeń technologicznych oraz procedur ochrony danych.
- Wsparcie eksperckie: współpraca z profesjonalistami umożliwia dostęp do konsultacji z ekspertami w danej dziedzinie, co przekłada się na precyzyjniejsze i bardziej wiarygodne tłumaczenia.
- Oszczędność czasu i zasobów: choć początkowe koszty mogą być wyższe, inwestycja w profesjonalne usługi minimalizuje ryzyko konieczności poprawek oraz związanych z tym dodatkowych kosztów i opóźnień.
Podsumowanie
Precyzyjna komunikacja jest kluczowym elementem w każdej działalności biznesowej. Niezależnie od sektora, w którym firma działa, jakość przekazywanych informacji może mieć znaczący wpływ na jej reputację, relacje z klientami oraz ogólną efektywność operacyjną.
W kontekście tłumaczeń nieprecyzyjne przekazanie treści może prowadzić do:
- Błędnej interpretacji dokumentów prawnych, co może skutkować kosztownymi konsekwencjami prawnymi.
- Utraty zaufania klientów, co może wpłynąć na lojalność i długoterminowe relacje.
- Problemów w zarządzaniu międzynarodowymi projektami, gdzie precyzja i klarowność są kluczowe dla sukcesu.
W jaki sposób zarówno tłumaczenia AI, jak i tłumaczenia wykonywane przez profesjonalistów mogą przyczynić się do sukcesu biznesu?
Tłumaczenia AI oraz tłumaczenia wykonywane przez profesjonalnych tłumaczy mają swoje unikalne zalety i ograniczenia. Rozważenie tych aspektów pozwala firmom na wykorzystanie obu metod w sposób efektywny:
Tłumaczenia AI
Tłumaczenia oparte na sztucznej inteligencji (AI) oferują szybkość i skalowalność, co czyni je atrakcyjnymi dla wielu firm. Kilka głównych korzyści obejmuje:
- Szybkość: algorytmy AI mogą przetłumaczyć duże ilości tekstu w krótkim czasie.
- Koszt: narzędzia te często są tańsze niż zatrudnienie profesjonalnego tłumacza.
- Dostępność: powszechnie dostępne narzędzia online umożliwiają szybki dostęp do usług tłumaczeniowych.
Jednakże korzystanie wyłącznie z tłumaczeń AI niesie ze sobą ryzyka związane z brakiem zrozumienia kontekstu kulturowego oraz specyfiki językowej. Przykładowo:
Tłumaczenie techniczne instrukcji obsługi maszyn przemysłowych może być precyzyjne pod względem terminologii technicznej, ale może zawierać błędy gramatyczne lub stylistyczne, które zmniejszają jej czytelność i użyteczność. …albo odwrotnie – poprawne językowo zdania, którym brakuje terminologii fachowej.
Profesjonalni Tłumacze
Profesjonaliści w dziedzinie tłumaczeń oferują niezrównane zrozumienie kontekstu oraz specyficznych niuansów językowych. Korzyści wynikające z ich pracy obejmują:
- Jakość: profesjonalni tłumacze dostarczają teksty najwyższej jakości, które są dokładne i spójne pod względem językowym.
- Precyzja: ich umiejętności pozwalają na dokładne oddanie intencji autora oryginalnego tekstu.
- Kontekst kulturowy: tłumacze mają wiedzę na temat lokalnych norm i zwyczajów, co jest kluczowe w komunikacji międzykulturowej.
Przykład zastosowania profesjonalnego tłumacza:
Podczas negocjacji międzynarodowych kontraktów handlowych, precyzyjne tłumaczenie dokumentów jest niezbędne do uniknięcia nieporozumień prawnych i finansowych.
Strategiczne podejście do tłumaczeń
Właściwe zarządzanie procesem tłumaczenia, uwzględniające zarówno tłumaczenia AI, jak i korzystanie z usług profesjonalnych tłumaczy, może przyczynić się do sukcesu biznesu. Oto kilka praktycznych wskazówek:
- Identyfikacja priorytetów: określ, które treści wymagają najwyższej precyzji i największego zrozumienia kontekstu kulturowego. Te obszary powinny być delegowane do profesjonalistów.
- Kontrola jakości: przeprowadzaj regularne audyty tłumaczeń AI, aby wykrywać ewentualne błędy i poprawiać je. Możesz również korzystać z narzędzi do automatycznego sprawdzania jakości tłumaczeń lub biura tłumaczeń.
- Współpraca z tłumaczami: jeśli korzystasz z usług profesjonalnych tłumaczy, utrzymuj otwartą komunikację i współpracę, aby zapewnić jak najwyższą jakość tłumaczeń.
- Doskonalenie procesów: monitoruj efektywność tłumaczeń, aby identyfikować obszary do doskonalenia i wprowadzać ulepszenia w procesach.
Poprawna i precyzyjna komunikacja jest kluczowa dla sukcesu biznesu na rynku międzynarodowym. Wykorzystanie zarówno tłumaczeń AI, jak i usług profesjonalnych tłumaczy może pomóc firmom osiągnąć ten cel i rozwijać się globalnie.
Sztuczna inteligencja to potężne narzędzie w branży tłumaczeniowej, oferujące znaczące korzyści w zakresie efektywności i kosztów. Jednakże, jak każda zaawansowana technologia, wymaga ona umiejętnego zastosowania. Podchodzimy do AI z entuzjazmem, ale i rozwagą. Połączenie ludzkiego doświadczenia z możliwościami sztucznej inteligencji, dzięki temu osiągamy optymalne rezultaty, łącząc szybkość i efektywność kosztową AI z niezastąpioną ludzką kreatywnością i zrozumieniem niuansów językowych.
Kluczem do sukcesu jest świadomość zarówno potencjału, jak i ograniczeń AI. Odpowiedzialne zarządzanie tymi technologiami pozwala nam wykorzystać ich zalety, jednocześnie minimalizując potencjalne ryzyka. To podejście gwarantuje, że nasze tłumaczenia nie tylko spełniają, ale często przewyższają oczekiwania klientów pod względem jakości, precyzji i bezpieczeństwa.
Translax łączy to, co najlepsze w człowieku i maszynie, zapewniając usługi tłumaczeniowe na najwyższym poziomie.
Translax a tłumaczenia AI
Warto podkreślić, że świat tłumaczeń AI nie ogranicza się do powszechnie znanych narzędzi jak ChatGPT. W rzeczywistości, istnieje szeroka gama rozwiązań online oraz lokalnych, działających na serwerach biur tłumaczeń. Dzielą się one na te dostępne publicznie oraz te przeznaczone wyłącznie do użytku wewnętrznego. W translax, podobnie jak inne postępowe agencje tłumaczeniowe, inwestujemy w samodzielnie tworzone, trenowane lub dostosowywane (fine-tuned) modele AI. Te zaawansowane rozwiązania pozwalają nam iść naprzód wraz z postępem technologicznym, jednocześnie zachowując pełną kontrolę nad procesem tłumaczenia. Co istotne, korzystanie z tłumaczeń AI nie zawsze oznacza wysyłanie poufnych tekstów do zewnętrznych firm takich jak Microsoft, Google czy OpenAI. Nasze wewnętrzne rozwiązania AI działają lokalnie, bez połączenia z internetem, co gwarantuje 100% bezpieczeństwa danych naszych klientów. Dzięki temu możemy oferować innowacyjne, wydajne i jednocześnie w pełni bezpieczne usługi tłumaczeniowe.
Masz pytania?

5 kluczowych aspektów skutecznej lokalizacji stron internetowych
Lokalizacja strony internetowej to kompleksowy proces dostosowywania istniejącej strony internetowej do lokalnej kultury i języka na rynku docelowym. Jest to krytyczny aspekt międzynarodowej strategii biznesowej firmy, wykraczający poza zakres prostego tłumaczenia i obejmujący wiele kluczowych aspektów, w tym niuanse kulturowe, estetykę projektowania, dynamikę rynku, przepisy prawne i zachowania użytkowników.
Na pierwszy rzut oka można pokusić się o stwierdzenie, że lokalizacja stron internetowych polega przede wszystkim na tłumaczeniu treści. Chociaż tłumaczenie jest rzeczywiście kluczowym elementem, skuteczna lokalizacja strony internetowej obejmuje znacznie więcej. Obejmuje modyfikację i dostosowanie różnych elementów strony internetowej, takich jak obrazy, symbole, kolory, formatowanie i opcje płatności, zapewniając, że strona jest w pełni dostosowana do docelowych odbiorców. Celem jest sprawienie, aby zlokalizowana strona internetowa wyglądała tak, jakby została oryginalnie zaprojektowana i stworzona na rynku docelowym.
Skuteczna lokalizacja witryny otwiera również potencjał do wyższych pozycji w wyszukiwarkach. Integrując strategie SEO z lokalizacją, firmy mogą zoptymalizować swoją widoczność w wyszukiwarkach na rynkach docelowych. Może to skutkować większym ruchem organicznym, prowadzącym do wzrostu liczby odwiedzających.
Ważne jest jednak, aby zrozumieć, że skuteczna lokalizacja strony internetowej nie jest prostym zadaniem. Wiąże się to z wieloma zawiłościami i wymaga przemyślanego, strategicznego podejścia. Proces ten wymaga połączenia biegłości językowej, zrozumienia kulturowego, umiejętności technicznych i znajomości lokalnego rynku. W tym miejscu rola profesjonalnego biura tłumaczeń staje się niezbędna. Wykorzystując swoją wiedzę i zasoby, może poprowadzić klienta przez złożony krajobraz lokalizacji stron internetowych, zapewniając dokładność, stosowność i skuteczność.
Kluczem do udanej lokalizacji strony internetowej jest zrozumienie jej złożoności, uznanie jej znaczenia i skrupulatne wykonanie jej przy użyciu profesjonalnej wiedzy.
Pięć kluczowych aspektów (adaptacja kulturowa, SEO, interfejs użytkownika, tłumaczenie treści, kwestie techniczne)
Pięć kluczowych aspektów lokalizacji witryny to adaptacja kulturowa, optymalizacja pod kątem wyszukiwarek (SEO), interfejs użytkownika (UI), tłumaczenie treści i kwestie techniczne. Każdy z nich odgrywa kluczową rolę w zapewnieniu, że witryna jest dobrze dopasowana do docelowych odbiorców i zapewnia płynne wrażenia użytkownika.
-
- Adaptacja kulturowa: adaptacja kulturowa jest prawdopodobnie jednym z najważniejszych elementów skutecznej lokalizacji strony internetowej. Obejmuje to dostosowanie treści i projektu strony internetowej, aby zapewnić ich zgodność z kulturą, tradycjami, wartościami i normami społecznymi odbiorców docelowych. Dotyczy to elementów wizualnych, takich jak obrazy, symbole i kolory, a także aspektów funkcjonalnych, takich jak formaty daty i godziny, waluta i jednostki miary. Na przykład pewne kolory lub symbole mogą mieć określone konotacje kulturowe w niektórych krajach, które znacznie różnią się od ich interpretacji w innych. Staranne dostosowanie tych elementów może pomóc uniknąć nieporozumień kulturowych, zwiększyć znaczenie strony internetowej dla lokalnych odbiorców, a ostatecznie zwiększyć zaangażowanie użytkowników i konwersje.
- SEO: SEO jest nieodzownym aspektem lokalizacji stron internetowych. Aby skutecznie dotrzeć do zamierzonych odbiorców, zlokalizowana witryna musi być widoczna w wyszukiwarkach na rynku docelowym. Wiąże się to z dogłębnym zrozumieniem lokalnych zachowań związanych z wyszukiwaniem, przeprowadzeniem badań słów kluczowych w języku docelowym oraz odpowiednią optymalizacją metatagów, tagów alt i treści. Ponadto ważne jest, aby wziąć pod uwagę techniczne czynniki SEO, takie jak struktura adresów URL i szybkość ładowania witryny, które mogą mieć wpływ na ranking witryny w wynikach wyszukiwania. Integrując strategie SEO z działaniami lokalizacyjnymi, firmy mogą poprawić swoją widoczność online na rynku docelowym, zwiększyć ruch organiczny oraz zwiększyć liczbę potencjalnych klientów i konwersji.
- Interfejs użytkownika (UI): interfejs użytkownika strony internetowej odgrywa kluczową rolę w określaniu doświadczenia użytkownika. Dobrze zlokalizowany interfejs użytkownika powinien być intuicyjny, łatwy w nawigacji i zgodny z preferencjami oraz oczekiwaniami lokalnych użytkowników. Obejmuje to dostosowanie układu strony, menu, przycisków, formularzy i innych interaktywnych elementów. Ponadto ważne jest, aby wziąć pod uwagę kontekst użytkownika, taki jak urządzenia i przeglądarki najczęściej używane na rynku docelowym, i upewnić się, że witryna jest z nimi kompatybilna. Optymalizując interfejs użytkownika, firmy mogą zapewnić płynniejsze, bardziej satysfakcjonujące doświadczenie użytkownika, co skutkuje zwiększonym zaangażowaniem i retencją użytkowników.
- Tłumaczenie treści: tłumaczenie treści stanowi podstawę lokalizacji strony internetowej. Nie chodzi jednak tylko o dosłowne tłumaczenie. Skuteczne tłumaczenie treści obejmuje przekazywanie tego samego komunikatu, tonu i wpływu emocjonalnego w języku docelowym, co w języku źródłowym. Wymaga to dogłębnego zrozumienia zarówno języka źródłowego, jak i docelowego, kontekstu kulturowego i tematu. Profesjonalne biuro tłumaczeń może zapewnić, że przetłumaczona treść jest nie tylko poprawna językowo, ale także odpowiednia kulturowo i skuteczna w rezonowaniu z lokalnymi odbiorcami.
- Uwagi techniczne: kwestie techniczne mają zasadnicze znaczenie dla zapewnienia, że zlokalizowana strona internetowa działa płynnie i zapewnia odpowiednie wrażenia użytkownika. Obejmuje to takie elementy jak architektura strony internetowej, praktyki kodowania, struktury adresów URL, projektowanie baz danych oraz integracja z lokalnymi systemami płatności i wysyłki. Ponadto podczas projektowania i rozwijania strony internetowej należy wziąć pod uwagę aspekty związane z lokalizacją, takie jak kierunek pisowni (od lewej do prawej lub od prawej do lewej), zestawy znaków oraz rozszerzanie lub kurczenie tekstu. Zapewnienie prawidłowej obsługi tych aspektów technicznych może pomóc uniknąć potencjalnych problemów funkcjonalnych, problemów ze zgodnością i frustracji użytkowników, przyczyniając się do lepszego doświadczenia użytkownika i wyższego poziomu jego zadowolenia.
Dlaczego te aspekty mają znaczenie
Znaczenie tych elementów polega na ich wspólnym wpływie na wrażenia użytkownika, wizerunek marki, ekspozycję, a ostatecznie na wyniki finansowe firmy na rynku docelowym. Oto głębsze spojrzenie na to, dlaczego każdy z tych aspektów ma niebagatelne znaczenie.
-
- Adaptacja kulturowa: na globalnym rynku rezonowanie z lokalnymi odbiorcami w ich kontekście kulturowym ma kluczowe znaczenie dla zdobycia ich zaufania. Gdy strona internetowa odzwierciedla zrozumienie i szacunek dla lokalnej kultury, tradycji i norm społecznych, generuje poczucie swojskości i przynależności. Może to znacznie zwiększyć zaangażowanie użytkowników, lojalność i konwersje. Ponadto pomaga to uniknąć potencjalnych nieporozumień kulturowych lub urazów, które mogłyby zaszkodzić wizerunkowi marki. Dlatego adaptacja kulturowa nie jest tylko drobiazgiem, ale koniecznością w lokalizacji stron internetowych.
- SEO: SEO ma kluczowe znaczenie dla widoczności zlokalizowanej strony internetowej. Bez niego nawet najlepiej zaprojektowana i dostosowana kulturowo strona internetowa może pozostać niezauważona przez docelowych odbiorców. Optymalizując witrynę pod kątem lokalnych zachowań związanych z wyszukiwaniem i wykorzystania słów kluczowych, firmy mogą poprawić swoją pozycję na stronach wyników wyszukiwania (SERP) na rynku docelowym. Może to prowadzić do zwiększenia ruchu organicznego, potencjalnych klientów i konwersji, zwiększając zwrot z inwestycji (ROI) w działania lokalizacyjne. Co więcej, SEO przyczynia się do długoterminowej stabilności strony internetowej, dostosowując ją do stale ewoluujących algorytmów wyszukiwarek.
- Interfejs użytkownika (UI): interfejs użytkownika ma bezpośredni wpływ na użyteczność strony internetowej, wpływając na sposób, w jaki użytkownicy wchodzą z nią w interakcję i postrzegają markę. Zlokalizowany interfejs użytkownika, który odpowiada preferencjom i oczekiwaniom lokalnych użytkowników, może poprawić wrażenia użytkownika, ułatwiając i uprzyjemniając im poruszanie się po witrynie, znajdowanie potrzebnych informacji i wykonywanie pożądanych działań. Może to prowadzić do zwiększenia satysfakcji użytkowników, retencji i konwersji, przekładając się na lepsze wyniki biznesowe. I odwrotnie, źle zlokalizowany interfejs użytkownika może frustrować użytkowników, odstraszyć ich i zepsuć reputację marki.
- Tłumaczenie treści: treść jest narzędziem, za pomocą którego firma komunikuje się z odbiorcami, przekazuje przesłanie marki i przekonuje użytkowników do podjęcia działań. Dokładne, odpowiednie kulturowo i skuteczne tłumaczenie treści ma kluczowe znaczenie dla zapewnienia, że cele te są realizowane na rynku docelowym równie skutecznie, jak na rynku źródłowym. Pomaga to zachować spójność i wiarygodność przekazu marki, rezonuje z lokalnymi odbiorcami i inspiruje ich do zaangażowania się w markę. Bez tego witryna może stracić na znaczeniu, skuteczności i potencjale sukcesu na rynku docelowym.
- Uwagi techniczne: znaczenie kwestii technicznych polega na ich wpływie na funkcjonalność i wygodę użytkowania strony internetowej. Dobrze funkcjonująca, sprawna technicznie strona internetowa nie tylko zapewnia płynniejszą obsługę, ale także buduje zaufanie użytkowników do marki. Z drugiej strony, usterki techniczne, problemy funkcjonalne lub niezgodność z lokalnymi przepisami mogą prowadzić do poirytowania użytkowników, utraty wiarygodności i problemów prawnych. Dlatego też uwzględnienie kwestii technicznych ma kluczowe znaczenie dla płynnego działania, zadowolenia użytkowników i zgodności z prawem zlokalizowanej strony internetowej.
Każdy z tych aspektów ma znaczenie na swój własny, unikalny sposób, przyczyniając się do skuteczności, doświadczenia użytkownika i sukcesu zlokalizowanej strony internetowej. Rozumiejąc ich znaczenie i zapewniając ich staranne wdrożenie, firmy mogą zmaksymalizować swoje szanse na sukces w wysiłkach związanych z ekspansją międzynarodową.
Jak skutecznie wdrożyć te aspekty
Wdrożenie tych pięciu kluczowych aspektów lokalizacji witryny wymaga strategicznego, dobrze zaplanowanego podejścia.
Poniżej zagłębiamy się w każdy aspekt i badamy strategie ich skutecznego wdrażania.
1. Adaptacja kulturowa:
-
- Zrozumienie kultury docelowej: zacznij od przeprowadzenia dokładnych badań, aby zrozumieć kulturę docelową, normy społeczne, tradycje, wartości i wrażliwość. Może to obejmować badania online, ankiety i konsultacje z lokalnymi ekspertami kulturowymi lub rdzennymi mieszkańcami.
- Dostosowanie elementów wizualnych i funkcjonalnych: gdy już dobrze zrozumiesz lokalną kulturę, dostosuj elementy wizualne, takie jak obrazy, symbole, kolory i projekty, aby upewnić się, że są one odpowiednie kulturowo i możliwe do odniesienia. Podobnie, dostosuj aspekty funkcjonalne, takie jak formaty daty i godziny, waluta i jednostki miary, aby dopasować je do lokalnych zastosowań.
- Przeprowadzenie testów użyteczności: na koniec przeprowadź testy użyteczności z rodzimymi użytkownikami, aby upewnić się, że adaptacje kulturowe są skuteczne i dobrze przyjęte. Dokonaj niezbędnych zmian w oparciu o otrzymane informacje zwrotne.
2. SEO:
-
- Przeprowadź badanie lokalnych słów kluczowych: użyj narzędzi SEO, aby zidentyfikować najbardziej trafne i skuteczne słowa kluczowe w języku docelowym. Powinno to uwzględniać lokalne zachowania związane z wyszukiwaniem, różnice w używanym języku i konkurencję dla słów kluczowych.
- Optymalizacja treści i metatagów: po zidentyfikowaniu słów kluczowych zoptymalizuj treść witryny, metatagi, tagi alt i adresy URL za pomocą tych słów kluczowych. Upewnij się, że odbywa się to w sposób, który wydaje się naturalny i znaczący dla użytkowników oraz zgodny z wytycznymi wyszukiwarek.
- Monitorowanie wskaźników SEO: po uruchomieniu zlokalizowanej witryny monitoruj jej wskaźniki SEO za pomocą narzędzi takich jak Google Analytics. Przyjrzyj się wskaźnikom, takim jak ruch organiczny, współczynnik odrzuceń, średni czas trwania sesji i konwersje, aby ocenić skuteczność strategii SEO i wprowadzić niezbędne poprawki.
3. Interfejs użytkownika (UI):
-
- Zrozumienie lokalnych preferencji interfejsu użytkownika: zbadaj preferencje dotyczące interfejsu użytkownika docelowych odbiorców. Może to obejmować zrozumienie najczęściej używanych urządzeń i przeglądarek, preferowanych układów stron internetowych i stylów nawigacji oraz oczekiwań dotyczących elementów interaktywnych.
- Dostosowanie interfejsu użytkownika: na podstawie wyników badań dostosuj układ strony, menu nawigacyjne, przyciski, formularze i inne interaktywne elementy. Powinno to mieć na celu stworzenie intuicyjnego, łatwego w nawigacji i satysfakcjonującego doświadczenia użytkownika.
- Przeprowadzenie testów z użytkownikami: po dostosowaniu interfejsu użytkownika przeprowadź testy z użytkownikami natywnymi, aby ocenić ich skuteczność. Dokonaj niezbędnych zmian na podstawie otrzymanych informacji zwrotnych.
4. Tłumaczenie treści:
-
- Zaangażuj profesjonalne biuro tłumaczeń: w przypadku tłumaczenia treści zdecydowanie zaleca się zaangażowanie renomowanej agencji tłumaczeń, która zatrudnia native speakerów języka docelowego. Powinni oni mieć specjalistyczną wiedzę zarówno w języku źródłowym, jak i docelowym, głębokie zrozumienie kontekstu kulturowego i specjalizację w danej dziedzinie. Gwarantuje to, że treść jest nie tylko poprawna językowo, ale także odpowiednia kulturowo i skuteczna w przekazywaniu zamierzonego komunikatu.
- Korzystaj z pamięci tłumaczeniowej: aby zachować spójność tłumaczenia i zwiększyć wydajność, należy korzystać z narzędzi pamięci tłumaczeniowej. Narzędzia te przechowują wcześniej przetłumaczone frazy lub segmenty i sugerują je, gdy pojawiają się podobne teksty, zapewniając spójność i skracając czas tłumaczenia.
- Korekta i edycja: Po zakończeniu tłumaczenia zleć korektę i edycję innemu profesjonaliście. Zapewnia to dokładność, przejrzystość i skuteczność tłumaczenia.
5. Uwagi techniczne:
-
- Plan lokalizacji: od początkowych etapów projektowania i rozwoju witryny należy zaplanować lokalizację. Obejmuje to stosowanie właściwych praktyk kodowania przyjaznych dla internacjonalizacji, tworzenie elastycznej architektury witryny i planowanie obsługi języków od prawej do lewej, jeśli to konieczne.
- Należy wziąć pod uwagę lokalne przepisy i normy: zrozumienie i przestrzeganie lokalnych przepisów i standardów związanych z funkcjonalnością strony internetowej, prywatnością danych i bezpieczeństwem. Może to obejmować integrację z lokalnymi systemami płatności i wysyłki, zapewnienie zgodności z RODO lub przestrzeganie lokalnych standardów dostępności.
- Testowanie na wielu platformach: przed uruchomieniem przetestuj witrynę na wielu urządzeniach, przeglądarkach i systemach operacyjnych popularnych na rynku docelowym. Zapewnia to kompatybilność i płynne działanie na różnych platformach.
- Monitorowanie wydajności witryny: po uruchomieniu zlokalizowanej witryny należy regularnie monitorować jej wydajność. Zwróć uwagę na wszelkie problemy funkcjonalne lub błędy i szybko się nimi zajmij.
Należy zauważyć, że mimo pogrupowania tych czynności wiele z nich można wykonywać równolegle. Na przykład zrozumienie kultury docelowej oraz preferencji użytkowników w kwestii interfejsu można przeprowadzić w tym samym badaniu. Dlatego nie należy postrzegać powyższej listy, jako czeklisty zagadnień o określonym porządku, a raczej jako macierz naczyń połączonych.
Przykładowy plan (patrz: grafika na górze):
- Analiza – badanie kultury docelowej, preferencji dotyczących interfejsu oraz uwarunkowań prawnych. Analiza słów kluczowych na potrzeby pozycjonowania strony internetowej.
- Wytyczne – przekształcenie zebranych danych w wytyczne dla wszystkich specjalistów zaangażowanych w proces lokalizacji strony internetowej, dostarczenie wytycznych i upewnienie się, że są zrozumiałe.
- Tłumaczenie wszystkich treści korzystając z narzędzi CAT.
- Adaptacja – dostosowanie elementów wizualnych i funkcjonalnych oraz interfejsu użytkownika. Optymalizacja znaczników meta oraz optymalizacja tłumaczeń pod kątem wyszukiwarek internetowych.
- Testowanie na wielu platformach, urządzeniach i przeglądarkach internetowych. Przeprowadzenie testów użyteczności (ang. usability) oraz testów interfejsu użytkownika. Skonsolidowanie wszystkich wyników testów.
- Korekty – implementacja wszystkich zmian i poprawek, które okazały się niezbędne wskutek przeprowadzenia poprzedniego etapu.
- Monitoring – monitorowanie wydajności strony oraz wskaźników SEO, oraz ostatnie działania korygujące (jeśli jest taka potrzeba). Upewnienie się, że wszystkie lokalne przepisy i wymogi są spełnione.
Skuteczne wdrożenie tych aspektów wymaga starannego planowania, badań, wkładu ekspertów, testów użytkowników i ciągłego monitorowania. Przyjmując strategiczne podejście i zwracając uwagę na każdy z tych elementów, firmy mogą stworzyć zlokalizowaną stronę internetową, która nie tylko rezonuje z docelowymi odbiorcami, ale także zapewnia płynne, satysfakcjonujące wrażenia użytkownika i napędza rozwój biznesu na rynku docelowym.
Wnioski
Lokalizacja strony internetowej to złożony, wieloaspektowy proces, który wymaga strategicznego podejścia, skrupulatnego planowania i profesjonalnej wiedzy. Odpowiednio zlokalizowana witryna może silnie oddziaływać na lokalnych odbiorców, zwiększając ich zaangażowanie, wiarygodność i konwersje. Należy jednak pamiętać, że lokalizacja strony internetowej to proces, który wymaga ciągłej optymalizacji i dostosowywania do zmieniającej się dynamiki rynku i preferencji użytkowników. Ostatecznie, skuteczna lokalizacja strony internetowej to nie tylko mówienie w lokalnym języku; to zrozumienie i połączenie z lokalną kulturą.
Kontakt

Wybór odpowiedniego biura tłumaczeń do lokalizacji oprogramowania
Wprowadzenie do lokalizacji oprogramowania
W coraz bardziej połączonym świecie, w którym bariery w biznesie wciąż maleją, co raz więcej firm rozważa globalną ekspansję. Rozwój technologii cyfrowej zapewnił korporacjom platformy do eksportu swoich produktów i usług poza rynki lokalne. Jednym z istotnych aspektów tego globalnego cyfrowego krajobrazu jest oprogramowanie. Aby skutecznie dotrzeć na rynki międzynarodowe, firmy muszą upewnić się, że ich oprogramowanie mówi językiem użytkownika, zarówno dosłownie, jak i kulturowo. Proces ten nazywany jest lokalizacją oprogramowania.
Lokalizacja oprogramowania obejmuje dostosowanie produktu do potrzeb językowych, kulturowych i technicznych rynku docelowego. Proces ten wykracza daleko poza zwykłe tłumaczenie elementów tekstowych oprogramowania. Dotyczy to każdego aspektu, który wpływa na interakcję użytkownika z oprogramowaniem, w tym interfejsu użytkownika, elementów wizualnych, funkcjonalności, a nawet komunikatów o błędach. Celem lokalizacji oprogramowania jest zapewnienie płynnego doświadczenia użytkownika (UX), które sprawia wrażenie, jakby oprogramowanie zostało pierwotnie stworzone dla rynku docelowego.
Pomyśl o lokalizacji oprogramowania jako o swego rodzaju moście kulturowym. Z jednej strony mamy oprogramowanie zaprojektowane i opracowane z myślą o konkretnym rynku, często rodzimym rynku firmy. Po drugiej stronie mamy zupełnie inny rynek, z jego unikalnym językiem, normami kulturowymi, przepisami i standardami technicznymi. Lokalizacja oprogramowania łączy obie strony, zapewniając, że oprogramowanie może z powodzeniem przejść na nowy rynek bez utraty zamierzonego celu lub funkcjonalności.
W dziedzinie lokalizacji oprogramowania nawet najmniejsze szczegóły mają znaczenie. Weźmy na przykład pod uwagę formaty dat. Podczas gdy użytkownik w USA jest przyzwyczajony do formatu MM/DD/RRRR, użytkownik w wielu innych częściach świata oczekuje formatu DD/MM/RRRR. Może się to wydawać drobnym szczegółem, ale gdy użytkownik musi wprowadzić datę urodzenia lub datę ważności karty kredytowej, staje się to istotnym problemem z punktu widzenia użyteczności. Podobnie, separatory numeryczne, symbole walut, formaty czasu, kierunek tekstu (od lewej do prawej lub od prawej do lewej), a nawet interpretacje kolorów muszą być zlokalizowane, aby były przyjazne dla użytkownika oraz zgodne z intencją twórców.
Lokalizacja oprogramowania uwzględnia kwestie prawne i regulacyjne rynku docelowego. Zapewnia to zgodność oprogramowania z lokalnymi przepisami dotyczącymi prywatności danych, przepisami handlowymi i wszelkimi wymaganiami branżowymi.
Lokalizacja oprogramowania to skomplikowany proces angażujący wielu interesariuszy, w tym tłumaczy, programistów, projektantów UX i specjalistów ds. zapewniania jakości. Cały proces jest zazwyczaj zarządzany za pomocą systemu TMS, który obsługuje zarządzanie projektami, przepływ pracy i alokację zasobów. Często obejmuje to narzędzia do tłumaczenia wspomaganego komputerowo (CAT/L10n), które pomagają tłumaczom zachować spójność i poprawić wydajność.
Zasadniczo lokalizacja oprogramowania to kompleksowy, multidyscyplinarny proces mający na celu uczynienie oprogramowania powszechnie dostępnym i użytecznym. Lokalizując swoje oprogramowanie, korporacje mogą nie tylko wejść na globalne rynki, ale także okazać szacunek dla lokalnych kultur i języków, budując zaufanie i lojalność wśród swoich międzynarodowych użytkowników.
Znaczenie wyboru właściwej agencji
Ponieważ firmy dążą do rozszerzenia swojego zasięgu poza granice kraju, lokalizacja oprogramowania stała się kluczowym aspektem ich strategii rozwoju. Biorąc pod uwagę złożoność i zawiłości związane z tym procesem, wybór odpowiedniej agencji do obsługi lokalizacji oprogramowania może znacząco wpłynąć na globalny sukces korporacji. Znaczenie tego wyboru jest nie do przecenienia, ponieważ ma on znaczący wpływ na ogólne wrażenia użytkownika, globalny wizerunek marki, zgodność z przepisami, a ostatecznie na wyniki finansowe.
Poprawa doświadczenia użytkownika
U podstaw udanej lokalizacji oprogramowania leży lepsze doświadczenie użytkownika. Właściwa agencja rozumie znaczenie zapewnienia płynnego, intuicyjnego doświadczenia użytkownika, które jest natywne dla rynku docelowego. Biuro tłumaczeń nieposiadające doświadczenia lub zrozumienia kulturowego może błędnie interpretować i nieprawidłowo lokalizować krytyczne elementy oprogramowania, prowadząc do nieefektywnego lub frustrującego doświadczenia użytkownika. Z drugiej strony, doświadczona agencja zapewni, że oprogramowanie będzie łatwe w obsłudze, odpowiednie kulturowo i kompatybilne z lokalnymi wymogami. Ostatecznie prowadzi to do zwiększenia zaangażowania, satysfakcji i lojalności użytkowników.
Ochrona wizerunku marki
Oprogramowanie firmy często służy jako ważny punkt styku między marką a jej klientami. W związku z tym jakość i użyteczność tego oprogramowania może znacząco wpłynąć na wizerunek marki. Błędy w lokalizacji oprogramowania mogą prowadzić do negatywnych doświadczeń użytkowników, które mogą zepsuć reputację marki. Wybierając odpowiednie biuro tłumaczeń, zapewniasz, że Twoje oprogramowanie odzwierciedla ten sam poziom jakości i profesjonalizmu, który Twoja marka reprezentuje na rynku krajowym, utrzymując w ten sposób pozytywny globalny wizerunek marki.
Zapewnienie zgodności z przepisami
Świat to nie tylko mozaika języków i kultur, ale także ram prawnych i regulacyjnych. Zgodność z lokalnymi przepisami jest kluczowym aspektem lokalizacji oprogramowania. Obejmuje to takie aspekty jak przepisy dotyczące prywatności danych, wymagania dotyczące dostępności i przepisy branżowe. Doświadczone biuro tłumaczeń będzie miało wiedzę i doświadczenie, aby poruszać się w tych zawiłościach, zapewniając pełną zgodność oprogramowania z lokalnymi przepisami, chroniąc w ten sposób firmę przed potencjalnymi konsekwencjami prawnymi.
Usprawnienie procesu lokalizacji
Lokalizacja oprogramowania to złożony proces, który obejmuje wiele etapów, od tłumaczenia i lokalizacji tekstu po adaptację interfejsów użytkownika, testowanie i zapewnianie najwyższej jakości. Odpowiednia agencja będzie dysponować usprawnionymi przepływami pracy, zaawansowanymi narzędziami do zarządzania projektami i zespołem ekspertów, aby skutecznie zarządzać tym procesem. Wybierając kompetentne biuro tłumaczeń, można zaoszczędzić znaczną ilość czasu i zasobów, zapewniając jednocześnie terminowe i udane wprowadzenie oprogramowania na nowe rynki.
Wspieranie wzrostu przychodów
Wreszcie, wybór odpowiedniej agencji zajmującej się lokalizacją oprogramowania ma bezpośredni wpływ na wyniki finansowe firmy. Dobrze zlokalizowane oprogramowanie może znacznie zwiększyć zadowolenie i zaangażowanie użytkowników, prowadząc do zwiększenia wykorzystania, utrzymania klientów i rekomendacji. To z kolei może napędzać wzrost przychodów na nowych rynkach. Ponadto właściwa agencja może pomóc uniknąć potencjalnych strat wynikających z grzywien regulacyjnych, uszczerbku na reputacji marki lub kosztownych poprawek z powodu złej lokalizacji.
Wybór odpowiedniego biura tłumaczeń do lokalizacji oprogramowania jest strategiczną decyzją, która ma istotne konsekwencje dla globalnych wysiłków firmy w zakresie ekspansji. Jest to decyzja, którą należy podjąć ostrożnie, biorąc pod uwagę wiedzę specjalistyczną agencji, jej doświadczenie, możliwości technologiczne i zrozumienie rynku docelowego. Wybrana agencja staje się istotnym partnerem w podróży w kierunku międzynarodowego wzrostu, odgrywając kluczową rolę w kształtowaniu oprogramowania na rynki globalne. W związku z tym ich wybór wymaga dokładnych badań, starannego rozważenia i strategicznego przewidywania.
Kryteria wyboru do rozważenia
Wybór agencji zajmującej się lokalizacją oprogramowania wymaga kompleksowego zrozumienia kilku kluczowych kryteriów. Kryteria są mapą prowadzącą korporacje do współpracy z agencją, która jest zgodna z ich celami i zapewnia udaną ekspansję.
- Specjalizacja
Przede wszystkim kluczowe znaczenie ma ocena doświadczenia agencji w lokalizacji oprogramowania. W przeciwieństwie do zwykłego tłumaczenia lokalizacja oprogramowania wymaga dogłębnego zrozumienia kulturowych, językowych i technicznych niuansów rynku docelowego. Ponadto agencje powinny dysponować zespołem rodzimych lingwistów, konsultantów kulturowych i ekspertów technicznych, aby zapewnić wysoką jakość lokalizacji.
- Doświadczenie w branży
Doświadczenie agencji w konkretnej branży lub powiązanych dziedzinach jest cennym atutem. Doświadczenie to zapewnia agencji dogłębne zrozumienie specyficznej dla branży terminologii, praktyk, przepisów i oczekiwań klientów. Oznacza to również, że biuro tłumaczeń prawdopodobnie napotkało i pokonało wyzwania związane z lokalizacją oprogramowania w danej branży.
- Możliwości technologiczne
W szybko zmieniającym się świecie rozwoju oprogramowania wykorzystywanie najnowocześniejszych technologii nie podlega negocjacjom. Biuro tłumaczeń powinno stosować zaawansowane systemy zarządzania tłumaczeniami (TMS) i narzędzia do tłumaczenia wspomaganego komputerowo (CAT), które wspierają wydajność i spójność w projektach na dużą skalę. Dodatkowo powinni być biegli w obsłudze różnych formatów plików i integracji z systemami klienta.
- Procedury zapewnienia jakości
Solidny proces zapewniania jakości ma kluczowe znaczenie dla realizacji bezbłędnego projektu lokalizacji oprogramowania. Agencje powinny mieć systematyczne procedury obsługi etapów tłumaczenia, lokalizacji, testowania i przeglądu. Takie procesy mogą obejmować przeglądy językowe, testy funkcjonalne i testowanie w kontekście/interfejsie. Biuro tłumaczeń powinno również przestrzegać uznanych międzynarodowych standardów jakości, takich jak ISO 17100.
- Skalowalność
W miarę rozwoju firmy i ekspansji na kolejne rynki będziesz potrzebować agencji, która może skalować swoje działania, aby sprostać zmieniającym się potrzebom. Skalowalność obejmuje nie tylko obsługę większych ilości pracy, ale także zarządzanie wieloma językami i regionami jednocześnie.
- Zarządzanie projektami
Skuteczne zarządzanie projektami jest podstawą udanej lokalizacji oprogramowania. Biura tłumaczeń powinny zapewnić dedykowanego kierownika projektu, który służy jako pojedynczy punkt kontaktowy, koordynując pracę różnych zespołów, zarządzając terminami i rozwiązując wszelkie problemy, które mogą się pojawić.
- Środki bezpieczeństwa
Biorąc pod uwagę wrażliwy charakter informacji związanych z oprogramowaniem, agencja powinna wdrożyć silne środki bezpieczeństwa danych. Obejmuje to szyfrowanie danych, umowy o zachowaniu poufności, bezpieczne przechowywanie danych i protokoły obsługi poufnych informacji.
- Obsługa klienta
Wysokiej jakości agencja powinna priorytetowo traktować obsługę klienta, zapewniając przejrzystą komunikację, szybkie odpowiedzi i satysfakcjonujące rozwiązywanie konfliktów. Opinie i recenzje klientów mogą zapewnić cenny wgląd w zaangażowanie biura tłumaczeń w zadowolenie klientów.
- Udokumentowane osiągnięcia
Wreszcie, udokumentowane doświadczenie jest doskonałym wskaźnikiem niezawodności i wydajności agencji. Studia przypadków, referencje klientów i reputacja w branży mogą zapewnić dokładniejszy obraz tego, jak wygląda praca z agencją.
Należy pamiętać, że najtańsza lub najbliższa agencja nie zawsze jest najlepszym wyborem. Najlepsze partnerstwo to takie, w którym możliwości agencji są zgodne z potrzebami firmy, zarówno obecnymi, jak i przyszłymi, zapewniając produktywną i długotrwałą relację. Inwestycja czasu i wysiłku w proces wyboru może przygotować grunt pod udaną lokalizację oprogramowania, umożliwiając firmie pozytywne i wpływowe wejście na nowe rynki.
Referencje
Referencje mogą zapewnić nieoceniony wgląd w umiejętności, niezawodność i etos obsługi klienta danej agencji. Przedstawiają one konkretne dowody kompetencji i sukcesów biura tłumaczeń, zapewniając potencjalnym klientom świadomą perspektywę tego, czego mogą oczekiwać od współpracy. Mogą zademonstrować podejście agencji do radzenia sobie z unikalnymi wyzwaniami, dostosowywania się do zmieniających się wymagań projektowych i zarządzania relacjami z klientami.
Podsumowanie
Proces wyboru agencji zajmującej się lokalizacją oprogramowania nie powinien być lekceważony. Jest to decyzja, która ma daleko idące konsekwencje dla globalnych planów ekspansji korporacji, postrzegania marki, doświadczeń użytkowników i ostatecznie jej wyników finansowych. Właściwa agencja może umożliwić korporacji przełamanie barier językowych i kulturowych, pomagając w skutecznym komunikowaniu propozycji wartości oprogramowania globalnym odbiorcom.
Lokalizacja oprogramowania wykracza poza zwykłe tłumaczenie językowe; obejmuje kompleksowe zrozumienie kultury docelowej, zachowań użytkowników, trendów rynkowych i otoczenia regulacyjnego. Jest to wielowymiarowy proces, który wymaga sprawności językowej, kompetencji kulturowych, wiedzy technicznej i skrupulatnego zarządzania projektem. W tym kontekście wybór kompetentnej, niezawodnej i doświadczonej agencji lokalizacji oprogramowania staje się krytyczną decyzją biznesową.
Wybór ten powinien opierać się na dokładnej ocenie wiedzy specjalistycznej biura tłumaczeń, jego doświadczenia w branży, możliwości technologicznych, procedur zapewniania jakości, skalowalności, zarządzania projektami, środków bezpieczeństwa danych, obsługi klienta i udokumentowanych osiągnięć. Ocena ta zapewnia, że wybrana agencja ma możliwości dostarczenia wysokiej jakości, kulturowo zniuansowanego i technicznie solidnego zlokalizowanego oprogramowania.
Referencje mogą służyć jako praktyczne dowody kompetencji i osiągnięć agencji. Zapewniają one potencjalnym klientom rzeczywisty wgląd w podejście agencji do rozwiązywania problemów, zdolności technologiczne, zaangażowanie w dotrzymywanie terminów i etos obsługi klienta. Oceniając referencje firmy mogą uzyskać świadomą perspektywę tego, czego mogą oczekiwać od partnerstwa z agencją.
Wybór odpowiedniego biura tłumaczeń to jednak dopiero pierwszy krok. Kolejne etapy obejmują budowanie solidnych, opartych na współpracy i przejrzystych relacji z agencją. Ważne jest, aby jasno komunikować swoje cele, oczekiwania i preferencje, upewniając się, że agencja w pełni rozumie unikalne wymagania oprogramowania. Podobnie ważne jest ustanowienie ustrukturyzowanego mechanizmu informacji zwrotnej, który pozwala na ciągłe doskonalenie i dostosowywanie się do zmieniających się potrzeb.
Ponadto należy pamiętać, że lokalizacja oprogramowania nie jest jednorazowym projektem, ale ciągłym procesem. W miarę rozwoju oprogramowania o nowe funkcje i aktualizacje, zlokalizowane wersje powinny być również szybko aktualizowane, aby zachować spójność i trafność. Wymaga to agencji, która może zapewnić stałe wsparcie, dostosowując się do zmieniających się potrzeb oprogramowania i zapewniając jego ciągły rezonans z docelowymi odbiorcami.
Wybór odpowiedniej agencji zajmującej się lokalizacją oprogramowania to wieloaspektowa decyzja, która wymaga starannego rozważenia, rzetelnych badań i strategicznego przewidywania. To inwestycja w globalny rozwój firmy, jej pozycję na rynku i zadowolenie klientów. Wysiłek i zasoby poświęcone temu procesowi mogą przynieść znaczące korzyści w postaci udanej, wpływowej i płynnej lokalizacji oprogramowania. Podczas gdy korporacje przechodzą przez ten złożony proces decyzyjny, ostatecznym celem powinno być znalezienie biura tłumaczeń, które jest zgodne z ich wartościami, spełnia ich potrzeby i napędza ich oprogramowanie do międzynarodowego sukcesu.
Kontakt:

Tłumaczenia maszynowe – pomocne narzędzie w rękach profesjonalnego tłumacza
Uniwersalna prawda głosi, że mylić się jest rzeczą ludzką. Zarówno z tego powodu, jak i dla zapewnienia odciążenia człowieka w jego codziennej pracy, stale wdraża się procesy automatyzacji niemal w każdej dziedzinie życia. Dotyczy to także tłumaczeń.
Tłumaczenia maszynowe nieustannie podlegają ulepszeniom i modyfikacjom oraz zyskują nowe możliwości. Czy oznacza to, że zawód tłumacza jest zagrożony wyparciem przez rozwiązania technologiczne? Przyjrzyjmy się temu zagadnieniu i sprawdźmy, czym są właściwie tłumaczenia maszynowe, co oferują i czy ich możliwości są większe od tych, które posiada człowiek.
Czym jest „tłumaczenie maszynowe”?
Początki tłumaczenia maszynowego (zwanego również tłumaczeniem automatycznym) sięgają XX w., a dokładniej zimnej wojny, kiedy to technikę tę zaczęto wykorzystywać do przekładu rosyjskiej dokumentacji na język angielski. A wszystko to dzięki rozwojowi lingwistyki obliczeniowej, która z kolei stosowana jest, poprzez użycie systemów informatycznych, do analizowania i rozumienia języka w mowie i piśmie. Lingwistyka obliczeniowa zajmuje się m.in udoskonalaniem tłumaczeń automatycznych, systemów rozpoznawania mowy czy syntezatorów mowy. Wszystkie te działania przekładają się realnie na działania biznesowe. Lingwistyka obliczeniowa angażowana jest chociażby do tworzenia zaawansowanych chatbotów, które pomagają internautom zaplanować podróż czy zrobić zakupy.
Najprostszą definicję tłumaczenia maszynowego podaje Słownik Języka Polskiego, wyjaśniając, iż jest to „tłumaczenie dokonywane za pomocą odpowiednio zaprogramowanego komputera[1]”.
Nieco bardziej rozwija to wyjaśnienie Wikipedia, według której tłumaczenia maszynowe to „dziedzina językoznawstwa komputerowego, która zajmuje się stosowaniem algorytmów tłumaczenia tekstu z jednego języka (naturalnego) na drugi[2]”.
Warto odwołać się także do Polskiej Normy PN-EN ISO 17100:2015, głoszącej, iż tłumaczenie maszynowe to „automatyczne tłumaczenie tekstu lub mowy z jednego języka naturalnego na inny przy użyciu systemu komputerowego[3]”.
Podsumowując powyższe informacje, tłumaczenie maszynowe (ang. Machine Translation), zwane też automatycznym, jest wykonywane w całości przez oprogramowanie komputerowe, bez ingerencji człowieka.
Powstaje przy użyciu:
- specjalistycznych algorytmów językowych,
- zestawów reguł gramatycznych,
- zbioru dostępnych przekładów (tzw. korpus tłumaczeniowy).
W dziedzinie, jaką stanowi językoznawstwo, korpus językowy pojmowany jest jako zbiór tekstów, obecnie występujący najczęściej w formie elektronicznej, w którym można wyszukiwać różne formy wyrazów i fraz. Wszystkie one przypisywane są konkretnym kategoriom gramatycznym, czyli podlegają tagowaniu.
PRZYKŁADWyraz TŁUMACZ otagowany zostanie jako rzeczownik, rodzaj męski, mianownik. Natomiast TŁUMACZYMY przypisane będzie do kategorii takich jak czasownik, pierwsza osoba liczby mnogiej, czas teraźniejszy.
Tłumaczenie automatyczne może odbywać się na kilka sposobów, w zależności od rodzaju systemu.
Tłumaczenie maszynowe – najpopularniejsze metody
Tłumaczenia maszynowe, jak zostało wspomniane we wstępie, stale podlegają modyfikacjom, mającym zwiększyć ich skuteczność. Istnieje zatem przynajmniej kilka metod, które, mniej lub bardziej, różnią się od siebie zasadą działania. Do najbardziej popularnych w historii rozwoju tłumaczeń automatycznych należą:
- tłumaczenie bezpośrednie – w tej metodzie zwroty z tekstu źródłowego zamieniane są bezpośrednio na tłumaczenie w oczekiwanym języku. Dzieje się tak, ponieważ program do tłumaczenia maszynowego zawiera bazę odpowiadających sobie par słów i najczęściej stosowanych fraz.
- przekład składniowy – program analizuje składnię tekstu i na jej podstawie dokonuje tłumaczenia.
- przekład międzyjęzykowy – opiera się na tłumaczeniu tekstu źródłowego w dwóch etapach. Najpierw tłumaczy się na język uniwersalny (tzw. interlinguę). Jest to sztuczny, międzynarodowy język pomocniczy, który łączy słownictwo romańskie z łatwą, regularną gramatyką. Dopiero tak powstały tekst tłumaczy się na język docelowy.
- przekład gramatyczny – metoda oparta na rozkładzie gramatycznym zdania. Oprogramowanie analizuje dokument źródłowy pod kątem gramatycznym i na jego podstawie tworzy model gramatyczny dla każdego zdania docelowego. Następnie otrzymany model gramatyczny języka źródłowego jest porównywany z modelem gramatycznym języka docelowego.
- tłumaczenie statystyczne – proces tłumaczenia maszynowego bazuje tutaj na tworzeniu rozbudowanych korpusów dwujęzycznych powstałych na bazie wcześniej tłumaczonych tekstów źródłowych. Na podstawie tych danych tworzone są statystyczne tablice korelacyjne. Dzięki nim słowa, zdania i zwroty w jednym języku są przyporządkowywane swoim odpowiednikom w języku obcym na zasadzie prawdopodobieństwa. Metoda ta nie jest dość skuteczna, ponieważ, aby osiągnąć zadowalające rezultaty tłumaczenia, baza tekstów źródłowych musi być bardzo obszerna i musi zawierać teksty o zbliżonej tematyce.
- tłumaczenie oparte na przykładach – metoda ta, podobnie jak statystyczna, również opiera się na korpusie dwujęzycznym. W tym przypadku jednak korpus jest wykorzystywany jako baza danych umożliwiająca utworzenie tłumaczenia na podstawie występujących w korpusie podobnych struktur tekstu źródłowego i odpowiadających mu tłumaczeń tego tekstu.
- Obecnie najbardziej rozwiniętym i precyzyjnym systemem jest neuronowe tłumaczenie maszynowe, które uczy się na podstawie wcześniej wykonanych przekładów. Sposób ten wyparł statystyczne tłumaczenie maszynowe.
Krytyka tłumaczenia maszynowego
Nieprzerwanie trwają dyskusje na temat efektywności tłumaczenia maszynowego. Tłumaczenie maszynowe z powodzeniem sprawdza się bowiem w przekładzie tekstów technicznych i wszelkiego typu instrukcji, które często zawierają powtarzalne elementy. Jest jednak tylko jednym z etapów procesu tłumaczeniowego.
Dlaczego więc, według nas, tłumaczenie maszynowe jest metodą nieopłacalną i mało wydajną? Spieszymy z odpowiedzią. Aby jakość tłumaczenia maszynowego była zadowalająca, przetłumaczony tekst był poprawny merytorycznie i językowo, a cały proces opłacalny, należy zgromadzić odpowiednio obszerną bazę (zazwyczaj około 200 000 nowych słów rocznie). Konieczna jest także wstępna obróbka językowa dokonana przez żywego tłumacza, mająca na celu przygotowanie tłumaczenia pod kątem określonej terminologii i zasad językowych do docelowych języków i dziedziny, której tekst dotyczy.
Po przetłumaczeniu tekstów z języka źródłowego metodą maszynową ponownie należy zaangażować w prace wykwalifikowanych tłumaczy-weryfikatorów i korektorów, których zadaniem jest ocenić jakość otrzymanego tekstu.
Tłumaczenie maszynowe warto więc stosować jedynie wtedy, gdy odbiorca chce poznać ogólny sens tekstu, bez zagłębiania się w szczegóły, zatem nie jest wymagany doskonały przekład. Znajduje to zastosowanie w przypadku prac badawczo-rozwojowych, w których tłumaczenia maszynowe używane są do przekazywania ogólnych informacji o zgłoszonych patentach, a dopiero później niektóre najbardziej interesujące fragmenty tekstu są przekazywane do pełnego tłumaczenia.
Tłumaczenie maszynowe jest także wykorzystywane przez firmy do przekładu obszernych, a zarazem mało widocznych i rzadko wykorzystywanych tekstów, takich jak bazy wiedzy, których pełne przetłumaczenie byłoby zbyt kosztowne.
Najczęściej jednak tekst otrzymany w wyniku tłumaczenia maszynowego powinien być zredagowany przez wykwalifikowanego tłumacza. W przeciwnym wypadku kontekst treści może być niewłaściwie ujęty lub tekst okaże się częściowo (lub nawet całkowicie) niezrozumiały. Wówczas bardzo prawdopodobne, że redakcja takiego tekstu będzie bardziej czasochłonna i kosztowna niż ponowne jego przetłumaczenie.
Podstawowe problemy napotykane przy tłumaczeniu maszynowym to:
- dwuznaczność i zmienność znaczeniowa wyrazów uwarunkowana czynnikami historycznymi i kulturowymi,
- metaforyczność,
- synonimia i różny zakres pojęciowy wyrazów,
- homonimia,
- różnice składniowe w języku źródłowym i docelowym,
- brak uwzględnienia rodzaju tłumaczonej treści.
Niekiedy tekst źródłowy jest już wstępnie przygotowywany w taki sposób, aby nie zawierał wieloznacznych sformułowań i był zgodny z określonymi zasadami językowymi, dotyczącymi używanej terminologii i struktury zdania języka docelowego – dzięki temu jakość tekstu otrzymanego po tłumaczeniu maszynowym zdecydowanie wzrasta. Ta procedura jest najczęściej stosowana w projektach, w których zespół kierujący całym procesem zarówno opracowuje tekst źródłowy, jak i zarządza samym tłumaczeniem. Wymaga to jednak dodatkowego nakładu pracy.
Reprezentujemy pogląd, że, pomimo ciągłego rozwoju programów komputerowych, techniki tłumaczenia maszynowego wciąż pozostają bardzo niedoskonałe, dlatego też Biuro Tłumaczeń Translax nie stosuje tłumaczenia maszynowego. Uważamy, że aby otrzymać tekst najwyższej jakości, udział wykwalifikowanych tłumaczy jest niezbędny. A wszystko to aby sprostać Państwa wymaganiom i stworzyć tłumaczenia spełniające Państwa oczekiwania.
Tłumaczenie maszynowe – czy warto?
Choć tłumaczenia maszynowe są coraz dokładniejsze i działają szybciej niż człowiek, wciąż nie mogą dorównać profesjonalnemu tłumaczowi. Jako biuro tłumaczeń, przeprowadzające audyty tłumaczeń, wciąż dostajemy do poprawy teksty, które zostały przygotowane właśnie tą metodą. Doskonale więc zdajemy sobie sprawę z tego, jak wadliwe bywają takie przekłady. Warto zatem dokonać audytu przetłumaczonej dokumentacji, jaką firma posiada w obiegu. Może się okazać, że zawiera pomyłki lub niespójności. Są one często efektem korzystania zarówno z usług tłumaczeniowych generowanych maszynowo, jak i dorywczo przez przypadkowych ludzi, bez stałej współpracy z jedną grupą profesjonalistów. Audyt tłumaczeniowy może obejmować nie tylko dokumentację, lecz także treści publikowane na stronach internetowych czy w ofertach.
Przekład automatyczny najczęściej nie jest dokładny, może też zawierać błędy albo nie oddawać w pełni sensu tekstu źródłowego. Nawet najbardziej zaawansowane algorytmy nie są wyczulone na niuanse językowe – dosłownie odczytują metafory, nie zawsze rozumieją wieloznaczności, brakuje im językowego wyczucia oraz intuicji. Wniosek jest prosty: żaden komputer nie zapewni jakości, która nie wymagałaby interwencji profesjonalisty.
Przykładem absurdalnych (a zarazem opłakanych w skutkach) błędów jest tłumaczenie na język węgierski, wykonane przez Google Translate – czołowego dostawcę tłumaczeń maszynowych. Tekst źródłowy „Niegazowane” Google tłumaczy jako „Nem szénsavas”, co oznacza „Niegazowany/Niegazowana/Niegazowane” (język węgierski jest niefleksyjny). Natomiast tłumaczenie słowa „niegazowane” (Zgadza się, zmieniono tylko wielkość litery!) tłumaczone jest tak: „még mindig”, co oznacza „wciąż/jeszcze/nadal”.

Idąc dalej, angielski zwrot „we’ve been blown away” często jest tłumaczony jako „zostaliśmy zdmuchnięci” – i to przez najlepsze maszyny (patrz: DeepL stan na 29.01.2023)! Ponadto niewłaściwie postawiony przecinek lub literówka w tekście źródłowym może wywieść automatycznego tłumacza na manowce. Tego typu błędy potrafią wygenerować rezultaty zupełnie sprzeczne z intencją autora, co oczywiście nie będzie miało miejsca w momencie, gdy tłumaczenie przygotowuje wykwalifikowany człowiek. Chociaż początkowo tłumaczenia wykonane maszynowo oparte na silnikach Machine i Deep Learning mogą wydawać się przyzwoite, specjaliści ostrzegają, że ich jakość odpowiada bezpłatnym lub tanim rozwiązaniom i nie może zastąpić tłumacza-człowieka (z wielu powodów).
Co więcej, niektóre programy, wykonujące tłumaczenia maszynowe, przechowują przekłady w swoich bazach danych. Nie można ich więc stosować w przypadku poufnych treści. To właśnie między innymi ze względu na bezpieczeństwo danych klientów nasze biuro nie używa systemów Machine Translation i korzysta wyłącznie z pracy doświadczonych tłumaczy.
Tłumaczenie maszynowe – kiedy warto?
Szereg wad nie oznacza jednak, że tłumaczenie maszynowe zupełnie pozbawione jest wszelkich zalet. Przede wszystkim pozwala ono zaoszczędzić czas i pieniądze. Za jego pomocą w krótkim czasie i niewielkim kosztem da się przełożyć bardzo dużą ilość tekstu. Oparte na Machine Translation programy działają błyskawicznie, a ich obsługa jest łatwa i intuicyjna.
Tłumaczenie automatyczne można więc z powodzeniem stosować w sytuacjach, w których akceptowane są ograniczenia i niedokładność, a priorytetem jest czas. Może być ono bardzo pomocne w ogólnym zrozumieniu sensu treści. Znakomicie sprawdzi się więc w celach prywatnych, np. do komunikacji w podróży zagranicznej albo tłumaczenia artykułu na stronie internetowej.
Tłumaczenia generowane maszynowo, wykorzystane w sposób umiejętny, mogą także usprawnić codzienną pracę tłumacza z tekstem. Pozwalają one opracować ogólny szablon, zwłaszcza w przypadku treści o standardowej konstrukcji. Bardzo podobnie bywają budowane np. niektóre pisma prawnicze czy administracyjne, a dodatkowo są one obszerne, więc wykorzystanie automatycznych rozwiązań oraz samodzielne dopracowanie tekstu wydaje się poprawnym pomysłem.
Kiedy tłumaczenie maszynowe to zły pomysł?
Obecnie w branży translatorskiej rozwija się, wspomniany uprzednio, trend łączenia pracy tłumacza i maszyny. Przyspiesza to realizację przekładów prostych, powtarzalnych tekstów. Jednak w sytuacji, kiedy jest potrzebne wnikliwe zrozumienie tekstu, jego intencji i celu, często skuteczniej jest bezpośrednio tłumaczyć tekst źródłowy.
Dlatego też przekład bardziej wymagających treści najlepiej od razu zlecić profesjonalnemu tłumaczowi. Dotyczy to między innymi dzieł artystycznych i poetyckich, np. powieści, tekstów piosenek, wierszy. Ich tłumaczenie nie może się bowiem obyć bez znajomości kulturowego i historycznego kontekstu, właściwej interpretacji i językowej wrażliwości, których brakuje sztucznej inteligencji.
Maszynowe tłumaczenie nie sprawdzi się również w przypadku materiałów biznesowych, sprzedażowych i marketingowych, które z zasady wymagają bardziej kreatywnego podejścia i wyczucia. Ich głównym celem jest w końcu budowanie relacji z potencjalnym klientem. Niedokładny przekaz oferty firmowej rodzi nieufność i świadczy o braku profesjonalizmu. Tłumaczenie automatyczne nie nadaje się również w przypadku tekstów branżowych i technicznych – algorytm może nie poradzić sobie ze specjalistycznym słownictwem.
Największym wyzwaniem tłumaczeń maszynowych są tzw. stringi (ciągi danych), czyli pojedyncze słowa tudzież frazy używane w przypadku tłumaczenia lub lokalizacji oprogramowania komputerowego (np. GUI lub firmware). Tłumaczenie wyrwanych z kontekstu zbiorów, złożonych ze specjalistycznych zwrotów, wymaga wielu konsultacji z klientem, zebrania materiałów referencyjnych, dostępu do oprogramowania, znalezienia w sieci dodatkowych informacji, aby zrozumieć jego działanie… Maszyna tego nie uczyni, a jedynie przetłumaczy słowa w najlepszy, swoim zdaniem, sposób.

Powyżej widzimy słowo „aligner”, które może być przełożone na wiele sposobów. Automat wybierze pierwsze, jego zdaniem, pasujące tłumaczenie i będzie je (w najlepszym wypadku) spójnie stosować do końca pliku. Oczywiście, maszyna nie skonsultuje się z klientem, aby sprawdzić, czy wybrała właściwy wariant.
Problem ten dotyczy również branży e-commerce, gdzie mamy do czynienia z lokalizacją oprogramowania i systemów oraz software house, czyli twórców oprogramowania dedykowanego. Podobnie jest w przypadku branży technicznej, w której tłumaczy się dużo rysunków z AutoCAD lub schematów elektrycznych i całych dokumentacji techniczno-rozruchowych. Bazują one (w pewnym stopniu) na dokumentach dostarczonych przez poddostawców komponentów, a ich jakość wejściowa nierzadko wymaga doprecyzowania, co autor miał na myśli. Rozwiązania maszynowe nie wykażą się proaktywnością, a w razie wątpliwości nie poproszą o dodatkowe wskazówki.
Lokalizacja posiada bardzo ważne, prawne podłoże. Prawie każdy kraj ma ustalone własne metody płatności stosowane w handlu elektronicznym. Niezlokalizowana strona sklepu internetowego może uniemożliwić zapłatę za produkt potencjalnemu lokalnemu klientowi, który, zniechęcony, zdecyduje najpewniej o przeniesieniu się na stronę innego sklepu. Podobnie sprawa wygląda w kwestii zasad i warunków, poufności danych, metryki i lokalnych wymogów, które dla każdego kraju mogą być zupełnie inne. Przestrzeganie przepisów nie tylko zapewni bezpieczeństwo podmiotowi i użytkownikowi, ale również wzbudzi zaufanie klientów.
Podsumowując, maszyna jest w stanie rozpoznać kontekst, czyli zrozumieć, że dane słowo otoczone słowami należy przetłumaczyć inaczej niż wtedy, gdy jest w towarzystwie innych wyrazów. Nie rozumie jednak, że tłumaczenie niektórych dokumentów wymaga specjalnego podejścia. Sztuczna inteligencja nie wie na przykład, że tłumaczenie tekstów z branży spożywczej wymaga zastosowania formuł i reguł z rozporządzeń prawa żywnościowego, a słowo „About” na stronie internetowej lub w programie oznacza „O nas”, a nie „Około”.
Tłumaczenie maszynowe – wybieraj świadomie
Tłumaczenie automatyczne zyskuje na popularności. W większości przypadków wciąż bardziej opłaca się jednak skorzystać z doświadczenia i wiedzy tłumacza. Tylko zlecenie tłumaczenia profesjonaliście daje gwarancję wysokiej jakości przekładu z zachowaniem odpowiedniego stylu i kontekstu. Takie tłumaczenie nie wymaga też dodatkowej weryfikacji i korekty, co – wbrew pozorom – może przełożyć się na szybsze i tańsze wykonanie przekładu. Dlatego przed podjęciem decyzji o sposobie przekładu weź pod uwagę charakter, cel i przeznaczenie tekstu. Pozwoli to uzyskać oczekiwaną jakość translacji i uniknąć katastrofalnych skutków błędnego tłumaczenia.
Szukasz partnera, który szybko dostarczy Ci doskonale przetłumaczone teksty? Skontaktuj się z nami. Wszystkie nasze treści są tłumaczone przez specjalistów, a nie maszyny – gwarantujemy poprawność przy szybkim czasie realizacji.
Trudno dziś wypatrywać tłumacza, który w swojej pracy bazuje jedynie na tradycyjnych słownikach. Wspierają go systemy, umożliwiające przesyłanie, monitorowanie i edytowanie dokumentów. Wyłapują one błędy, powtórzenia, proponują użycie określonych terminów w danym kontekście.
Opisywane narzędzia kryją się pod nazwą CAT, czyli Computer Aided Translation i mało który tłumacz jest w stanie wyobrazić sobie swoją pracę bez ich wsparcia.
Ogromną popularnością cieszy się także NMT, Neural Machine Translation. Dzięki temu systemowi tłumaczone są całe zdania, z uwzględnieniem kontekstu. NMT dobrze radzi sobie z morfologią i składnią, w niczym nie przypominając niezgrabnych treści, będących niegdyś efektem przekładu przez sztuczną inteligencję.
Czy specjalistyczne oprogramowania zawładną rynkiem i tłumacze staną się niepotrzebni? Nie ma obaw, każda technologia potrzebuje przecież profesjonalnego koordynatora.Dzięki nowoczesnemu i rozbudowanemu systemowi tzw. pamięci tłumaczeniowych (ang. Translation Memory) programy CAT znacznie przyspieszają i ujednolicają proces przekładu. Tego typu narzędzia są wręcz niezastąpione w wypadku tłumaczeń technicznych, w których nader często występują powtórzenia słów, nazw, a nawet całych zdań. Programy CAT to po prostu pomoc tłumacza.
Oprogramowanie CAT przede wszystkim przyspiesza oraz ułatwia pracę tłumaczowi, umożliwia mu wykonywanie szybszych i lepszych tłumaczeń, przez co poprawia jego konkurencyjność. Pozwala również na tworzenie baz tłumaczeniowych i terminologicznych, dzięki którym podnosi się jakość przekładów. Umożliwia łatwą redakcję jednolitych, profesjonalnych i konsekwentnych pod względem językowym tekstów. Programy CAT gwarantują także zachowanie spójności terminologicznej i stylistycznej. Profesjonalne narzędzia pozwalają na tłumaczenie dokumentów w niepopularnych formatach (np. InDesign, Quark, FrameMaker). Coraz częściej Klienci mają własne bazy terminologiczne i oczekują, że będą one stosowane. Dzięki programom CAT tłumacz może spełnić oczekiwania nawet najbardziej wymagających zleceniodawców. Omawiane narzędzia udoskonalają również programy do kontroli jakości (QA Distiller, X-Bench, QA Checker itp.).
Programy CAT są bardzo pomocne w wypadku tekstów w formatach elektronicznych, o dużym lub umiarkowanym stopniu powtarzalności (np. dokumenty rejestracyjne samochodu, odpis aktu urodzenia, instrukcje do urządzeń, licencje, umowy) bądź w przypadku tłumaczeń o zbliżonej tematyce dla jednego klienta. Nie pomogą natomiast w tłumaczeniach o dużym stopniu zróżnicowania tematycznego lub dla różnych zleceniodawców, którzy posiadają odmienne preferencje dotyczące stylistyki albo terminologii.
Niemal każde tłumaczenie tekstu nieliterackiego zawiera w sobie pewne powtarzające się fragmenty. W zależności od charakteru materiału są to poszczególne nazwy, frazy, albo nawet całe zdania. Bywa też tak, że zdania różnią się od siebie zaledwie jednym lub dwoma słowami. W takich sytuacjach zupełnie naturalną i logiczną czynnością jest skorzystanie z wcześniej przetłumaczonych fraz, skopiowanie ich i wklejenie ich (po dokonaniu ewentualnych poprawek) we właściwe miejsce. Właśnie w takich momentach z pomocą przychodzą tłumaczom programy typu CAT.
W największym uproszczeniu: programy te są jak suflerzy – podpowiadają wcześniejsze tłumaczenie, jeśli dany fragment tekstu przypomina coś, co już wcześniej zostało przełożone.
Istnieją dwie zasadnicze kategorie programów typu CAT. Ze względu na funkcjonalność wyróżniamy programy przystosowane do współpracy z MS Word jako nakładki oraz programy z własnym, niezależnym edytorem tekstu. Pierwsza grupa umożliwia tłumaczowi pracę w doskonale znanym mu środowisku (grupa ta traci na popularności), natomiast programy CAT należące do drugiej grupy oferują większą elastyczność i wygodę, umożliwiając tłumaczenie szerokiej gamy formatów plików (m.in. HTM/HTML, XML/SGML, edytorów tekstowych, programów do składu DTP itd.). Większość programów CAT umożliwia obecnie tłumaczenie przynajmniej 50 formatów plików.
Praca z narzędziem CAT nie jest szczególnie skomplikowana, ale wymaga podstawowej wiedzy na temat możliwości i funkcji programu. Każdy plik, który poddajemy obróbce – dzielony jest na tzw. segmenty (TU – translation unit/jednostki tłumaczeniowe). Najczęściej są nimi zdania albo ich fragmenty, jeśli zdanie zawiera dwukropki, średniki, myślniki itd. Nie jest to jednak arbitralne – sposób segmentacji dokumentu może zostać spersonalizowany. Na przykład można zdefiniować funkcję dzielenia pliku tak, żeby uniknąć podziału zdania po „np.”.
Bez względu na to, czy program jest nakładką na MS Word, czy niezależnym narzędziem, CAT rozpoznaje, zapamiętuje i wyróżnia pierwszy segment (w Wordzie jest on wyróżniany graficznie, w edytorze wyświetlany w specjalnym oknie). Pojawią się wówczas dwa pola tekstowe: jedno z tekstem źródłowym, a drugie z tłumaczeniem lub miejscem na wpisanie tłumaczenia. Jeżeli pamięć tłumaczenia jest jeszcze pusta, bo tłumacz dopiero rozpoczął pracę, program nie będzie miał z czego czerpać podobnych fragmentów i jeszcze w niczym nie pomoże. Natomiast jeśli program ma już bazę, z której może skorzystać, to – w przypadku tekstu podobnego do niegdyś już przetłumaczonego – oprócz tekstu źródłowego pokaże propozycję przekładu wraz z informacjami dodatkowymi. Te dodatkowe informacje to najczęściej identyfikator autora poprzedniego tłumaczenia, data powstania przekładu itd. Program będzie wówczas wymagał zatwierdzenia wpisanego przekładu i automatycznie przejdzie do następnego segmentu. Graficzna oprawa tekstu pozwala tłumaczowi już na pierwszy rzut oka stwierdzić, czy fragment tekstu jest identyczny z tym, który występuje w bazie, czy podobny w mniejszym lub większym stopniu. Szacowana zgodność określana jest również procentowo, a różnice są wyraźnie oznaczane kolorami.
W miarę postępujących prac translatorskich programy CAT tworzą tzw. pamięć tłumaczeń (Translation Memory), czyli bazę, na podstawie której działają.
Im większa, bardziej pojemna i zróżnicowana pamięć, tym lepiej dla tłumacza. Szeroka baza pojęć zwiększa szansę na znalezienie podobnych segmentów w kolejnych tłumaczeniach.
Jak to działa w praktyce? Bardzo obrazowym przykładem jest tłumaczenie instrukcji obsługi różnych urządzeń. Często urządzenia są udoskonalane i powstają ich nowe wersje. Przykładowo Produkt 1000 firmy X może się różnić od Produktu 2000 tej samej firmy zaledwie kilkoma funkcjami, które oczywiście należy uwzględnić również w jego instrukcji obsługi. Dysponując pamięcią tłumaczeniową z przekładu instrukcji Produktu 1000, z łatwością można stworzyć tłumaczenie instrukcji obsługi Produktu 2000, wzbogaconego o nowe funkcje. Będący w posiadaniu takiej bazy tłumacz może w kilkanaście sekund policzyć całkowitą objętość tekstu oraz liczbę nowych segmentów, które różnią się od tekstu już wcześniej przetłumaczonego. W takiej sytuacji może się okazać, że w tekście o objętości 60 tys. słów nowe fragmenty to zaledwie 5%! Nie trzeba więc nikogo przekonywać, że takie tłumaczenie zajmuje o wiele mniej czasu niż pisanie całkiem nowego tekstu. Ponadto duże międzynarodowe firmy same korzystają z narzędzi CAT do przygotowania plików do tłumaczeń i przechowują własne bazy pamięci tłumaczeniowych. Dzięki temu po wysłaniu takiego pliku do tłumacza firma może zachować stylistykę i terminologię wszelkich wcześniejszych tłumaczeń.
Programy CAT umożliwiają bardzo łatwe i szybkie przeszukiwanie pamięci tłumaczeń. Jeżeli jakieś słowo było już kiedyś przetłumaczone, za pomocą zaledwie paru kliknięć myszy czy też kombinacji klawiszowych można odnaleźć wszystkie segmenty, w których kiedykolwiek występował dany termin (funkcja concordance).
Co ważne, programy tego typu pozwalają na zdefiniowanie funkcji, które odpowiadają za rozpoznawanie pewnych fragmentów tekstu (tzw. placeables), i kopiowanie ich za pomocą skrótu klawiszowego z tekstu źródłowego do wykonywanego w danej chwili tłumaczenia. Jest to funkcja bardzo przydatna w wypadku nazw produktów, dat (programy CAT przy okazji konwertują je na inny format), wartości liczbowych itd.
Wszystkie marki programów CAT posiadają własne moduły zarządzania terminologią lub umożliwiają współpracę z modułami peryferyjnymi – można więc zsynchronizować z takim narzędziem wszelkiego rodzaju słowniki, które podpowiadają prawidłowe tłumaczenia zdefiniowanych pojęć.
Należy jednak zawsze pamiętać o tym, że nie wszystkie tłumaczenia będą wykonywane za pomocą programów CAT z podobną skutecznością. Używanie jednej pamięci do wszystkich tłumaczeń również może się okazać złym pomysłem. Przykładowo baza tłumaczeniowa, która powstała na podstawie tłumaczenia programów komputerowych, nie przyda się w tłumaczeniach regulaminów sklepów internetowych, a pamięć tłumaczeniowa z zakresu medycyny nie znajdzie zastosowania w lokalizacji oprogramowania i tłumaczenia plików XML, SGML lub HTML.
Narzędzia CAT opierają się na następujących funkcjach:
- Segmentowanie tłumaczonego tekstu, czyli dzielenie go na jednostki (zdania lub fragmenty zdań). Taka forma podziału tekstu znacznie ułatwia i przyspiesza tłumaczenie. Często tekst oryginalny i tekst tłumaczony znajdują się w dwóch sąsiadujących ze sobą okienkach, dzięki czemu tłumacz może na bieżąco kontrolować przebieg procesu przekładu.
- Tekst oryginalny i tekst tłumaczony traktowane są jako tzw. jednostka tłumaczeniowa. Jednostki takie są zapisywane w specjalnej bazie i tłumacz może z nich korzystać, wykonując kolejne zlecenia o podobnej tematyce.
- Korzystanie z tzw. pamięci tłumaczeniowych (są to specjalne pliki), w których przechowywane są jednostki tłumaczeniowe, czyli odpowiadające sobie fragmenty tekstu oryginalnego i przetłumaczonego z dokumentów, które wcześniej zostały przetłumaczone. Dzięki temu tłumacz może w dowolnym momencie korzystać z przetłumaczonych fragmentów (fuzzy matching), co znacznie przyspiesza pracę i zapewnia spójność tłumaczenia.
Zdecydowana większość biur tłumaczeń w Polsce stosuje narzędzia CAT – nie tylko ze względu na skrócenie czasu realizacji czy ograniczenie kosztu tłumaczenia, lecz także dla kontroli QA Checker (Trados Studio), kompatybilności z plikami w formatach DTP (IDML, MIF) i IT/PASSOLO (XML, SGML, HTM, HTML, PO, MO, SRT, VTT, TBULIC) oraz rozbudowywania własnej bazy tłumaczeniowej TM. Na rynkach zachodnich prawie wszystkie biura korzystają z co najmniej jednego narzędzia CAT. Biuro Tłumaczeń Translax prowadzi szkolenia z obsługi najważniejszych programów CAT dla tłumaczy i menedżerów projektu. Takie zajęcia pozwalają zapoznać się z możliwościami tych narzędzi, dzięki czemu tłumaczenie nawet trudnych tekstów technicznych będzie przebiegać sprawniej przy jednoczesnym zachowaniu najwyższej jakości przekładu.
Tłumaczenie maszynowe – trendy branżowe
Wiele źródeł, między innymi artykuł tcworld, sugeruje że biura tłumaczeń oraz tłumacze-freelancerzy powinni dostosowywać się do nadchodzących zmian w branży, jakimi są sieci neuronowe oraz podpięte pod nie systemy automatyzujące. Czy powinniśmy jednak w pełni ufać automatom? Czy maszyny nie potrzebują operatorów, a ramiona robotyczne programistów? W końcu nawet autopilot Tesli nie jest nieomylny i także tak nowoczesnym autom zdarzają się wypadki.
Tłumaczenia maszynowe prawdopodobnie zostaną z nami na dłużej, ale każdy projekt tłumaczony w ten sposób powinien być dobrze przemyślany (przynajmniej w modelu micro-SWOT). Przekład automatyczny przyjdzie z odsieczą w przypadku bardzo specyficznych potrzeb:
- odpowiedniej tematyki,
- dopasowanego korpusu tłumaczeniowego (danych z bazy poprzednich tłumaczeń),
- dużego wolumenu treści przy krótkim terminie realizacji,
- wykwalifikowanego zespołu korektorów MTPE oraz ekspertów MT (ds. tłumaczeń maszynowych).
Jak wynika z danych CSA Research odsetek projektów dla klientów końcowych korzystających z tłumaczeń maszynowych wzrósł z 13% w 2019 r. do 24% w 2020 r. W ostatnim czasie najlepszą jakość tłumaczenia maszynowego zanotowano w treściach związanych z oprogramowaniem komputerowym, usługami prawnymi i telekomunikacją (Intento). Z jakimi dziedzinami programy tłumaczeniowe kiepsko sobie radzą? Według statystyk jest to przekład treści z zakresu usług profesjonalnych i biznesowych, instrukcji użytkowania oraz sprzedaży i marketingu.
Tłumacze, korzystający ze wsparcia programów do przekładu automatycznego motywują to następującymi argumentami[4]:
- oszczędność czasu (86%),
- zapewnienie spójności terminologii (83%)
- poprawa jakości tłumaczenia (70%).
Jak widać, tłumaczenia maszynowe, choć na obecnym etapie mają swoje wady i ewidentne niedociągnięcia, mogą stać się użytecznym narzędziem w rękach wykwalifikowanego tłumacza. Przed rozpoczęciem projektu należy więc przeanalizować wszelkie za i przeciw oraz zastosować właściwe podejście i procesy.
[1]https://sjp.pwn.pl/sjp/tlumaczenie-maszynowe;2529806.html z dn. 07.11.2022
[2]https://pl.wikipedia.org/wiki/T%C5%82umaczenie_automatyczne z dn. 07.11.2022
[3] A.D Kubacki, M. Łomzik Systemy przekładu maszynowego w pracy tłumacza języka niemieckiego, Orbis Linguarum vol. 52/2018, str. 132.
[4](PDF) Badanie pamięci tłumaczeniowych 2006: Postrzeganie przez użytkowników korzystania z tm (researchgate.net) z dn. 10.11.2022 r.
W razie pytań zapraszamy do kontaktu:

Słów kilka o lokalizacji gier komputerowych [aktualizacja]
W dzisiejszych czasach gry komputerowe są jedną z najbardziej popularnych form rozrywki – dogoniły już (a być może nawet wyprzedziły) kino, telewizję, czy książki – szczególnie w dzisiejszych czasach. Dowodem na to są wzrastające obroty światowych producentów gier. Z uwagi na fakt, iż większość gier na polskim rynku jest produkcji zagranicznej, muszą one zostać zlokalizowane – ich treść jest dostosowywana przez tłumaczy i specjalistów od IT do warunków językowo-kulturowych typowych dla naszego rynku zbytu, który często znacznie różni się od rynku pierwotnego. Oczywiście nie można zapomnieć o naszych rodzimych produkcjach, które mamy okazje tłumaczyć na język angielski, niemiecki, chiński, japoński, hiszpański, portugalski lub francuski.
Lokalizacja gier komputerowych to jedna z najnowocześniejszych dziedzin tłumaczenia, która w Polsce zaistniała dopiero w latach 70-tych XX w. Wówczas jednak tłumaczenie gier ograniczało się jedynie do przekładu dostępnych w menu opcji, nigdy nie ingerowało za to w treść samej gry. Zmieniło się to wraz z postępem technicznym. Na przełomie lat 90-tych XX w. i pierwszego dziesięciolecia XXI w. w naszym kraju pojawiły się pierwsze profesjonalne tłumaczenia gier z języka angielskiego. Przekłady te odznaczały się bardzo wysoką jakością wykonania. Pierwszy przekład gry „Planescape” po przetłumaczeniu zajmował objętość aż około 5000 stron! A postępujący rozwój technologii nastręczał tłumaczom coraz to nowych problemów i wyzwań.
Dziś tłumacz, który zajmuje się lokalizacją gier komputerowych, musi mierzyć się z rozmaitymi trudnościami. Pierwszym problematycznym czynnikiem przy lokalizacji gier jest ogromna presja czasu. Proces tworzenia większości gier komputerowych zajmuje od jednego roku do trzech lat (a w skrajnych przypadkach nawet całe życie developera). W niektórych przypadkach tłumaczenie rozpoczyna się zaraz po ukończeniu scenariusza, jednakże zazwyczaj odbywa się najczęściej dopiero wtedy, gdy gra jest już w zasadzie gotowa (beta). A lokalizacja musi zakończyć się przecież przed jej światową premierą, co sprawia, że termin realizacji tłumaczenia jest nieprzekraczalny. Przez to często trzeba zaangażować w projekt większą liczbę tłumaczy. Presja czasu i praca w grupie nie są jednak jedynymi trudnościami, z jakimi borykają się tłumacze. Mają oni bowiem często dostęp jedynie do papierowego scenariusza, bez możliwości obejrzenia gry. Znacznie utrudnia to rozwiązywanie niejasności, jakie napotykają w trakcie tłumaczenia. Kolejnym kluczowym elementem jest wpływ jakości przekładu na tzw. „grywalność” (ang. gameplay). Gry komputerowe różnią się bowiem od siebie pod względem historii, które opowiadają, stopnia interakcji, zasad rozgrywki, a także odniesieniami do elementów kultury. Różnorodność tematyczna, jaką charakteryzują się współczesne gry, wymaga od tłumacza wykształcenia w wielu dziedzinach, dzięki któremu da on radę sprostać wymaganiom danego projektu lokalizacyjnego.
Wiedza tłumacza na temat gier komputerowych nie powinna się jednak ograniczać do znajomości pojęcia grywalności. Tłumacz musi mieć także podstawowe wykształcenie informatyczne – musi być zaznajomiony m.in. ze strukturą i zasadami działania kodu źródłowego, bowiem usunięcie lub dodanie choćby jednego znaku w jakimkolwiek miejscu w kodzie źródłowym może spowodować w najlepszym przypadku przerwanie gry, w najgorszym natomiast uszkodzenie całego komputera. Na szczęście debugger dba o poprawność kodu (walidację), by uniknąć trwałych problemów.
Na szczęście lokalizacja gier komputerowych (w zasadzie nie tylko komputerowych, bo mamy jeszcze gry na konsole oraz urządzenia mobilne) jest ułatwiona, jeśli chodzi o kwestie techniczne specjalistycznymi narzędziami wspomagającymi proces przekładu (CAT tools). Programy tylko Trados lub MemoQ dbają m.in. o spójność stylistyczną (baza tłumaczeniowa), terminologiczną (glosariusz) – szczególnie w przypadku dzielenia projektu na kilkoro tłumaczy – oraz techniczną – oferując m.in. system walidacji, który nie pozwoli na finalizację projektu zawierającego błędy techniczne typu usunięcie znacznika z kodu itp.
Lokalizacja gier komputerowych wymaga od tłumacza także znajomości technik używanych w tłumaczeniach audiowizualnych, dla których typowe są takie elementy jak podpisy oraz limity znaków w nich wykorzystywanych, wyskakujące okna, synchronizacja ruchu warg, a także ograniczenia czasowe i przestrzenne.
W ramach projektu lokalizacyjnego oprócz samej gry tłumaczy się także inne rodzaje tekstów. Do najczęściej tłumaczonych tekstów należą: instrukcja, opakowanie gry, plik readme, strona internetowa gry (również materiały np. na Kickstarter), dialogi do dubbingu i podpisów (np. SRT lub VTT) oraz grafiki tekstowe (rastrowe/bitmapy), jak również cały GUI, czyli interfejs graficzny użytkownika (zawsze z limitem znaków). Instrukcje obsługi zawierają dokładne wskazówki, w jaki sposób można wykorzystać wszystkie możliwości gry. Częściowo są to także teksty reklamowe – mają za zadanie przedstawić grę w możliwie najatrakcyjniejszy sposób. Tekst na opakowaniu gry jest mini-odpowiednikiem instrukcji. Podobnie jak ona jest reklamą gry, jednak bardzo krótką ze względu na ograniczenia przestrzenne. Z kolei strona internetowa ma przyciągać nowych nabywców, ale także – dzięki forom internetowym i mediom społecznościowym – zachęcać stałych klientów, do dokonywania kolejnych zakupów. Marketingowy flow jest więc u tłumacza jak najbardziej w cenie (choć nie ma mowy o wolnej amerykance – niezbędny jest Brief od klienta). Plik readme jest zazwyczaj technicznym tekstem, który w zwięzłej formie opisuje działanie gry, minimalne wymagania sprzętowe potrzebne do jej komfortowego (pod kątem UX) użytkowania oraz wprowadzone nowości i błędy usunięte z oprogramowania. Tworzenie dialogów na potrzeby dubbingu oraz napisów to z kolei zadanie wymagające od tłumacza dużej kreatywności i elastyczności. W przypadku podpisów/list dialogowych należy pamiętać również o zasadach składu tekstu „pod” subtitling (np. limit ilości wierszy wyświetlanych jednocześnie, limit znaków na wiersz, brak tzw. sierotek itd.) – jazdą bez trzymanki są momenty, w których należy przetłumaczyć (w formie list dialogowych) jednocześnie wypowiedź bohatera oraz tekst wyświetlany na ekranie. Elementy takie jak rejestr, odmiana języka, a także słownictwo typowe dla danej postaci w grze komputerowej muszą zostać przeniesionego do języka docelowego. Innymi słowy, muszą zostać zlokalizowane. Ograniczona ilość czasu i miejsca na wypowiedź nastręcza jednak wielu trudności. Nie można zapomnieć również o tzw. grafikach tekstowych, czyli wielowarstwowych obrazach, w których jedna z warstw zawiera tekst wymagający przetłumaczenia. Przykładami takich grafik są: logo/tagline gry, tytuł na opakowaniu oraz komponenty tekstowe zawarte w grafice samej gry.
Poza warstwą językową i techniczną w procesie lokalizacji gier wiele zależy od konspektu i schematu blokowego całej koncepcji, jak również mechanizmu struktur algorytmicznych. Niektóre gry korzystają z potężnych silników nawet, gdy nie jest to niezbędne (ale na pewnym etapie upraszcza lub/oraz przyspiesza proces produkcji), a nieraz wręcza odwrotnie – w myśl zasady KISS (and. keep it simple stupid) – stosunkowo skomplikowane elementy są hard kodowane efektywnie – bez zbędnych bibliotek – co zupełnie zmienia koncept technologiczny. Ważne jest też to, czy gra jest tworzona od razu w kilku językach, czy tworzono ją tylko na jeden rynek, a jej sukces spowodował chęć przeniesienia jej na dodatkowe rynki. W takiej sytuacji niezbędne może okazać się poddanie gry procesowi internacjonalizacji (i18n), czyli takiej zmiany kodu sprzed kompilacji, by łatwo można było wydobyć wszystkie stringi do tłumaczenia, a implementację tłumaczenia ograniczyć do importu – bez ręcznego i ryzykownego „kopiuj & wklej”.
Po implementacji tłumaczeń należy przeprowadzić testowanie gry, czyli: importuje się treści, przeprowadza suchą walidację, potem debugowanie, a na końcu próbną kompilację pod kątem kontroli błędów i ostrzeżeń (szczególnie w kontekście plików i bibliotek zależnych). Po stworzeniu pierwszej wersji pre-stable należy wysłać ją do tłumaczy do „przejścia/przeklikania”. Tłumacze raportują (w specjalnym formularzu) teksty, które należy poprawić (wskazując m.in. wagę i ilość danego błędu opatrując go komentarzem). Poprawki można zaimplementować poprzez poprawienie dostarczonego wcześniej (do walidacji i kompilacji) kodu lub nanieść je ręcznie po stronie developera na skorygowanym kodzie po debugowaniu. Decyzje podejmuje klient – w oparciu o dane dotyczące ilości roboczogodzin spędzonych na przygotowaniu pierwszej kompilacji. Jeśli proces trwał kilka lub kilkanaście godzin, to nie warto wracać – w procesie – tak bardzo, by robić to ponownie. Raport poprawek i usprawnień jest przygotowywany w taki sposób, by zmiany w tłumaczeniach mogła nanosić również osoba, która nie zna danego języka obcego.
Informacje te są zaledwie wierzchołkiem góry lodowej – każdy projekt powinien być traktowany indywidualnie, co wymaga doskonałego przygotowania zaplecza po stronie developera i oddelegowanie tłumaczenia gry biuru tłumaczeń lub oddelegowanie całego procesu lokalizacji gry, gdy developer nie czuje się pewnie w eksporcie, implementacji i kontroli przetłumaczonych materiałów przed publikacją (nie każdy producent gry jest „od razu” biegły w produkcji tytułów na wiele rynków). Współpraca software house lub gamedev z biurem tłumaczeń jest bezcenna – tej usługi nie powinno się zlecać bez przygotowania zaplecza, rozmów i zwarcia szeregów.
Teraz znają już Państwo podstawy lokalizacji gier komputerowych. Biuro Tłumaczeń TRANSLAX oferuje Wam tę usługę z gwarancją terminowości i najwyższej jakości. Specjaliści współpracujący z naszym biurem są doświadczeni i w pełni profesjonalni. Zaufało nam już wielu Klientów (m.in. Playlink, T-Bull, MythicOwl, Nawia Games, Raba Games, BAAD Games, Gamezaur, Klabater, Immersion, Nesalis Games…). Dołącz do nich! Prześlij wzór NDA na biuro@translax.eu lub skorzystaj z formularza kontaktowego!

Narzędzia CAT – oprogramowanie wspomagające tłumacza [aktualizacja]
CAT, czyli Computer Aided Translation, to nazwa obejmująca wszelkiego rodzaju narzędzia usprawniające pracę tłumacza.
Dzięki nowoczesnemu i rozbudowanemu systemowi tzw. pamięci tłumaczeniowych (ang. Translation Memory) programy CAT znacznie przyspieszają i ujednolicają proces przekładu. Tego typu narzędzia są wręcz niezastąpione w wypadku tłumaczeń technicznych, w których nader często występują powtórzenia słów, nazw, a nawet całych zdań. Programy CAT to po prostu pomoc tłumacza.
Oprogramowanie CAT przede wszystkim przyspiesza oraz ułatwia pracę tłumaczowi, umożliwia mu wykonywanie szybszych i lepszych tłumaczeń, przez co poprawia jego konkurencyjność. Pozwala również na tworzenie baz tłumaczeniowych i terminologicznych, dzięki którym podnosi się jakość przekładów. Umożliwia łatwą redakcję jednolitych, profesjonalnych i konsekwentnych pod względem językowym tekstów. Programy CAT gwarantują także zachowanie spójności terminologicznej i stylistycznej. Profesjonalne narzędzia pozwalają na tłumaczenie dokumentów w niepopularnych formatach (np. InDesign, Quark, FrameMaker). Coraz częściej Klienci mają własne bazy terminologiczne i oczekują, że będą one stosowane. Dzięki programom CAT tłumacz może spełnić oczekiwania nawet najbardziej wymagających zleceniodawców. Omawiane narzędzia udoskonalają również programy do kontroli jakości (QA Distiller, X-Bench, QA Checker itp.).
Programy CAT są bardzo pomocne w wypadku tekstów w formatach elektronicznych, o dużym lub umiarkowanym stopniu powtarzalności (np. dokumenty rejestracyjne samochodu, odpis aktu urodzenia, instrukcje urządzeń, licencje, umowy) bądź w przypadku tłumaczeń o zbliżonej tematyce dla jednego klienta. Nie pomogą natomiast w tłumaczeniach o dużym stopniu zróżnicowania tematycznego lub dla różnych zleceniodawców, którzy posiadają odmienne preferencje dotyczące stylistyki albo terminologii.
Niemal każde tłumaczenie tekstu nieliterackiego zawiera w sobie pewne powtarzające się fragmenty. W zależności od charakteru materiału są to poszczególne nazwy, frazy, albo nawet całe zdania. Bywa też tak, że zdania różnią się od siebie zaledwie jednym lub dwoma słowami. W takich sytuacjach zupełnie naturalną i logiczną czynnością jest skorzystanie z wcześniej przetłumaczonych fraz, skopiowanie ich i wklejenie ich (po dokonaniu ewentualnych poprawek) we właściwe miejsce. Właśnie w takich momentach z pomocą przychodzą tłumaczom programy typu CAT.
W największym uproszczeniu: programy te są jak suflerzy – podpowiadają wcześniejsze tłumaczenie, jeśli dany fragment tekstu przypomina coś, co już wcześniej zostało przełożone.
Istnieją dwie zasadnicze kategorie programów typu CAT. Ze względu na funkcjonalność wyróżniamy programy przystosowane do współpracy z MS Word jako nakładki oraz programy z własnym, niezależnym edytorem tekstu. Pierwsza grupa umożliwia tłumaczowi pracę w doskonale znanym mu środowisku (grupa ta traci na popularności), natomiast programy CAT należące do drugiej grupy oferują większą elastyczność i wygodę, umożliwiając tłumaczenie szerokiej gamy formatów plików (m.in. HTM/HTML, XML/SGML, edytorów tekstowych, programów do składu DTP itd.). Większość programów CAT umożliwia obecnie tłumaczenie przynajmniej 50 formatów plików.
Praca z narzędziem CAT nie jest szczególnie skomplikowana, ale wymaga podstawowej wiedzy na temat możliwości i funkcji programu. Każdy plik, który poddajemy obróbce – dzielony jest na tzw. segmenty (TU – translation unit/jednostki tłumaczeniowe). Najczęściej są nimi zdania albo ich fragmenty, jeśli zdanie zawiera dwukropki, średniki, myślniki itd. Nie jest to jednak arbitralne – sposób segmentacji dokumentu może zostać spersonalizowany. Na przykład można zdefiniować funkcję dzielenia pliku tak, żeby uniknąć podziału zdania po „np.”.
Bez względu na to, czy program jest nakładką na MS Word, czy niezależnym narzędziem, CAT rozpoznaje, zapamiętuje i wyróżnia pierwszy segment (w Wordzie jest on wyróżniany graficznie, w edytorze wyświetlany w specjalnym oknie). Pojawią się wówczas dwa pola tekstowe: jedno z tekstem źródłowym, a drugie z tłumaczeniem lub miejscem na wpisanie tłumaczenia. Jeżeli pamięć tłumaczenia jest jeszcze pusta, bo tłumacz dopiero rozpoczął pracę, program nie będzie miał z czego czerpać podobnych fragmentów i jeszcze w niczym nie pomoże. Natomiast jeśli program ma już bazę, z której może skorzystać, to – w przypadku tekstu podobnego do niegdyś już przetłumaczonego – oprócz tekstu źródłowego pokaże propozycję tłumaczenia wraz z informacjami dodatkowymi. Te dodatkowe informacje to najczęściej identyfikator autora poprzedniego tłumaczenia, data powstania przekładu itd. Program będzie wówczas wymagał zatwierdzenia wpisanego tłumaczenia i automatycznie przejdzie do następnego segmentu. Graficzna oprawa tekstu pozwala tłumaczowi już na pierwszy rzut oka stwierdzić, czy fragment tekstu jest identyczny z tym, który występuje w bazie, czy podobny w mniejszym lub większym stopniu. Szacowana zgodność określana jest również procentowo, a różnice są wyraźnie oznaczane kolorami.
W miarę postępujących prac translatorskich programy CAT tworzą tzw. pamięć tłumaczeń (Translation Memory), czyli bazę, na podstawie której działają.
Im większa, bardziej pojemna i zróżnicowana pamięć, tym lepiej dla tłumacza. Szeroka baza pojęć zwiększa szansę na znalezienie podobnych segmentów w kolejnych tłumaczeniach.
Jak to działa w praktyce? Bardzo obrazowym przykładem jest tłumaczenie instrukcji obsługi różnych urządzeń. Często urządzenia są udoskonalane i powstają ich nowe wersje. Przykładowo Produkt 1000 firmy X może się różnić od Produktu 2000 tej samej firmy zaledwie kilkoma funkcjami, które oczywiście należy uwzględnić również w jego instrukcji obsługi. Dysponując pamięcią tłumaczeniową z przekładu instrukcji Produktu 1000, z łatwością można stworzyć tłumaczenie instrukcji obsługi Produktu 2000, wzbogaconego o nowe funkcje. Będący w posiadaniu takiej bazy tłumacz może w kilkanaście sekund policzyć całkowitą objętość tekstu oraz liczbę nowych segmentów, które różnią się od tekstu już wcześniej przetłumaczonego. W takiej sytuacji może się okazać, że w tekście o objętości 60 tys. słów nowe fragmenty to zaledwie 5%! Nie trzeba więc nikogo przekonywać, że takie tłumaczenie zajmuje o wiele mniej czasu niż pisanie całkiem nowego tekstu. Ponadto duże międzynarodowe firmy same korzystają z narzędzi CAT do przygotowania plików do tłumaczeń i przechowują własne bazy pamięci tłumaczeniowych. Dzięki temu po wysłaniu takiego pliku do tłumacza firma może zachować stylistykę i terminologię wszelkich wcześniejszych tłumaczeń.
Programy CAT umożliwiają bardzo łatwe i szybkie przeszukiwanie pamięci tłumaczeń.
Jeżeli jakieś słowo było już kiedyś przetłumaczone, za pomocą zaledwie paru kliknięć myszy czy też kombinacji klawiszowych można odnaleźć wszystkie segmenty, w których kiedykolwiek występował dany termin (funkcja concordance).
Co ważne, programy tego typu pozwalają na zdefiniowanie funkcji, które odpowiadają za rozpoznawanie pewnych fragmentów tekstu (tzw. placeables), i kopiowanie ich za pomocą skrótu klawiszowego z tekstu źródłowego do wykonywanego w danej chwili tłumaczenia. Jest to funkcja bardzo przydatna w wypadku nazw produktów, dat (programy CAT przy okazji konwertują je na inny format), wartości liczbowych itd.
Wszystkie marki programów CAT posiadają własne moduły zarządzania terminologią lub umożliwiają współpracę z modułami peryferyjnymi – można więc zsynchronizować z takim narzędziem wszelkiego rodzaju słowniki, które podpowiadają prawidłowe tłumaczenia zdefiniowanych pojęć.
Należy jednak zawsze pamiętać o tym, że nie wszystkie tłumaczenia będą wykonywane za pomocą programów CAT z podobną skutecznością. Używanie jednej pamięci do wszystkich tłumaczeń również może się okazać złym pomysłem. Przykładowo baza tłumaczeniowa, która powstała na podstawie tłumaczenia programów komputerowych, nie przyda się w tłumaczeniach regulaminów sklepów internetowych, a pamięć tłumaczeniowa z zakresu medycyny nie znajdzie zastosowania w lokalizacji oprogramowania i tłumaczenia plików XML, SGML lub HTML.
Narzędzia CAT opierają się na następujących funkcjach:
- Segmentowanie tłumaczonego tekstu, czyli dzielenie go na jednostki (zdania lub fragmenty zdań). Taka forma podziału tekstu znacznie ułatwia i przyspiesza tłumaczenie. Często tekst oryginalny i tekst tłumaczony znajdują się w dwóch sąsiadujących ze sobą okienkach, dzięki czemu tłumacz może na bieżąco kontrolować przebieg procesu tłumaczenia.
- Tekst oryginalny i tekst tłumaczony traktowane są jako tzw. jednostka tłumaczeniowa. Jednostki takie są zapisywane w specjalnej bazie i tłumacz może z nich korzystać, wykonując kolejne tłumaczenia o podobnej tematyce.
- Korzystanie z tzw. pamięci tłumaczeniowych (są to specjalne pliki), w których przechowywane są jednostki tłumaczeniowe, czyli odpowiadające sobie fragmenty tekstu oryginalnego i przetłumaczonego z dokumentów, które wcześniej zostały przetłumaczone. Dzięki temu tłumacz może w dowolnym momencie korzystać z przetłumaczonych fragmentów (fuzzy matching), co znacznie przyspiesza pracę i zapewnia spójność tłumaczenia.
Najważniejsze programy CAT to m. in.:
– Pakiet Trados Studio – jego podstawą jest Translator´s Workbench, program zarządzający TM. W skład pakietu wchodzą ponadto: uniwersalny edytor, zestaw makr do pracy w edytorze MS Word, programy wspomagające tłumaczenie plików w formacie Excel i PowerPoint, program do tworzenia plików TM z wcześniejszych tłumaczeń, narzędzia umożliwiające tłumaczenie plików programów do składu oraz program do zarządzania terminologią niezależny pakiet oprogramowania pozwalający na zakładanie projektów (również z ewidencją zleceniodawców, diagramami Gantta itd.), zarządzanie plikami, pracę we wbudowanym edytorze kompatybilnym m.in. z tłumaczeniem programów komputerowych, plików XML, HTML i DTP, kontrolę jakości (w tym kontrolę pisowni i walidację techniczną), finalizację projektów, zarządzanie bazami tłumaczeniowymi oraz terminologicznymi i wiele więcej.
Tego oprogramowania nie trzeba przedstawiać chyba żadnemu tłumaczowi. Więcej informacji: https://pl.wikipedia.org/wiki/SDL_Trados_Studio
– SDLX – obecnie element pakietu Trados, program pracujący z użyciem własnego edytora nie występuje w sprzedaży. Możliwości programu:
- obsługa wielu formatów (m.in. FrameMaker, Quark, InDesign, XML, SGML, (X)HTML, Illustrator itp.),
- możliwość wykorzystywania wcześniejszych tłumaczeń poprzez rejestrowanie wykonanych przekładów,
- tworzenie baz terminologicznych (SDLTM, MDB, TMW, TMX),
- opcje/filtry Quality Assurance (QA Checker) oraz implementacja poprawek,
- automatyczne podpowiedzi tłumaczeń w trakcie pracy, ustawienia liczby podpowiedzi i głębokości wyszukiwania,
- zakładanie projektów tłumaczeniowych, dystrybucja (Trados Studio Professional) i finalizacja,
- analiza powtarzalności treści, wewnętrzne dopasowania rozmyte, perfect match i context match,
- tworzenie pamięci tłumaczeń z materiałów referencyjnych, baz terminologicznych, glosariuszy.
– MemoQ – nowy, bardzo dobry program, dynamicznie rozwijany, zdobywający coraz większą liczbę zwolenników.
Oprócz typowych cech programu CAT, takich jak: ułatwione tłumaczenie i weryfikacja tekstu, możliwość korzystania z pamięci tłumaczeń i wcześniej wypracowanych rozwiązań, tworzenie i rozbudowa baz terminologicznych, automatyczne podpowiedzi tłumaczeń, analiza powtarzalności (wraz z analizą jednorodności) tekstu źródłowego, ma zalety szczególne:
- obsługa formatów plików utworzonych w innych programach CAT (np. TTX TagEditor, Star Transit, SDLXLIFF Trados Studio),
- łączenie funkcjonalności edytora tekstu z zarządzaniem pamięciami tłumaczeń i bazami terminologicznymi oraz integracja z silnikami przedtłumaczania maszynowego,
- możliwość tworzenia projektów na serwerze MemoQ i dzielenia się pracą z innymi tłumaczami pracującymi nad projektem.
– OmegaT – jedyne całkowicie bezpłatne narzędzie CAT, dostępne dla większości systemów operacyjnych (program w języku Java). Ma wiele funkcji typowych dla oprogramowania CAT: tworzenie, import, eksport pamięci tłumaczeniowych, dopasowywanie tłumaczeń. Umożliwia również:
- tłumaczenie wielu plików w różnych formatach jednocześnie,
- korzystanie naraz z kilku pamięci tłumaczeń i słowników,
- kompatybilność z innymi narzędziami CAT, np. TRADOS Studio (SDLXLIFF),
- pracę w różnych systemach operacyjnych.
Dzięki licznym dodatkom OmegaT można rozbudować o kolejne przydatne funkcje. Interfejs programu jest całkowicie spolszczony.
– Across – program niedoceniany w naszym kraju, choć godny uwagi, ponieważ:
- w wersji dla freelancerów jest bezpłatny, można go więc starannie przetestować, poznając zalety programów CAT bez ponoszenia kosztów,
- może działać w dwóch trybach: jako samodzielny program lokalny lub połączony ze zdalnym serwerem,
- jest to zintegrowane środowisko pracy z bogatą listą możliwości,
- zawiera moduły pozwalające na tworzenie bazy Klientów, zarządzanie projektami, tworzenie glosariusza, kontrolę jakości.
– Matecat – kompatybilny (na chwilę obecną) z 79 formatami plików (od plików MS Office – również odpowiedniki OSX – przez MIF, IDML, XML, aż po pliki lokalizacyjne PO, RESX, TXML i wiele innych – patrz niżej). Jego zalety:
- jest darmowy i w pełni online (zaleca się używanie Chrome),
- jest wyposażony w silnik do przedtłumaczania maszynowego,
- przy odpowiedniej konfiguracji pamięci TM zachowujemy nasze jednostki tłumaczeniowe dla siebie (bez współdzielenia z producentem),
- umożliwia wgrywanie ZIP-ów i wskazywanie plików z Google Drive,
- umożliwia podzielenie projektu na kilkoro tłumaczy i ich równoległą pracę na współdzielonych zasobach (TM i TB).

– Muldrato – w pełni kompatybilny z plikami DWG i DXF, doskonały program do tłumaczenia dokumentacji CAD. Jego zalety:
- jest autonomiczny i niezależny od systemu CAD – posiadanie AutoCAD czy innych tego typu programów nie jest konieczne do pracy nad tłumaczeniem dokumentacji,
- pozwala eksportować teksty i automatycznie je optymalizować, analizować czcionki, teksty i rysunki,
- ma odpowiednie narzędzia i funkcje do tworzenia, edycji i optymalizacji słowników,
- nie wymaga ręcznego przetwarzania rysunków,
- wspiera każdy język.
Zdecydowana większość biur tłumaczeń w Polsce stosuje narzędzia CAT – nie tylko ze względu na skrócenie czasu realizacji czy ograniczenie kosztu tłumaczenia, lecz także dla kontroli QA Checker (Trados Studio), kompatybilności z plikami w formatach DTP (IDML, MIF) i IT (XML, SGML, HTM, HTML, PO, MO, SRT, VTT) oraz rozbudowywania własnej bazy tłumaczeniowej TM. Na rynkach zachodnich prawie wszystkie biura korzystają z co najmniej jednego narzędzia CAT. Biuro Tłumaczeń Translax prowadzi szkolenia z obsługi najważniejszych programów CAT dla tłumaczy i menedżerów projektu. Takie zajęcia pozwalają zapoznać się z możliwościami tych narzędzi, dzięki czemu tłumaczenie nawet trudnych tekstów technicznych będzie przebiegać sprawniej przy jednoczesnym zachowaniu najwyższej jakości przekładu.
Który program CAT wybrać?
Trados Studio posiada około 70% udziałów w rynku. Nie jest to narzędzie idealne, ale zaraz obok MemoQ jedno z najlepszych (choć ostatnio zdania są podzielone). Oba programy są równie kompatybilne (krzyżowo), funkcjonalne i wygodne (według indywidualnych preferencji). Sugerujemy, by przed podjęciem decyzji zapoznać się z wersjami testowymi. Oba programy różnią się tak niewielkimi detalami (przynajmniej w kwestii rezultatów, które uzyskujemy pracując z nimi), że z pewnością każdy z nich sprawdzi się w większości codziennych zadań. Osoby mające jednak inne zdanie mogą wybrać szkolenie z CAT: Trados Studio, Matecat, MemoQ, OmegaT lub Muldrato.
Przeprowadziliśmy niejedno szkolenie lub/oraz kurs z obsługi Trados Studio, MemoQ, Matecat, OmegaT, InDesign, Framemaker oraz z lokalizacji stron internetowych i oprogramowania. Przeszkoliliśmy m.in.: WSZOP w Katowicach, UAM w Poznaniu, SWPS w Warszawie, LOT, Whirlpool/Indesit, Getresponse, PIBR w Warszawie, SKWP w Warszawie, wielu pracowników biur tłumaczeń oraz dziesiątki freelancerów.
Na naszym kanale youtube można znaleźć kompletny, darmowy kurs/szkolenie z podstaw obsługi programu Trados Studio: https://bit.ly/szkolenie-trados
Zapraszamy!

DTP w pracy tłumacza
Doskonale wiemy, że w przypadku wielu tekstów znaczenie ma nie tylko to, jak są przetłumaczone, lecz także – jak wyglądają. Dlatego też w biurze tłumaczeń Translax oferujemy Państwu również usługi związane z DTP.
Tłumaczenia i DTP
DTP, czyli Desktop Publishing oznaczają czynności z zakresu prepress mające na celu stworzenie, rozwój i przygotowanie do druku publikacji w formie elektronicznej. Zgodnie z definicją z wikipedii (https://pl.wikipedia.org/wiki/DTP): termin oznaczający pierwotnie ogół czynności związanych z przygotowaniem na komputerze materiałów, które będą później powielone metodami poligraficznymi. Krócej mówiąc, termin ten oznacza komputerowe przygotowanie publikacji do druku.
Gdy zaistnieje potrzeba przetłumaczenia publikacji takiej jak ulotka, folder, katalog czy instrukcja obsługi, powinniśmy zadbać o to, żeby tłumaczenie dobrze spełniało swoją funkcję. Aby ulotka ciągle była ulotką, musi być atrakcyjna graficznie. Dlatego też niezbędna staje się współpraca tłumacza z grafikiem i specjalistą DTP. Po przetłumaczeniu tekst zmienia swoją objętość, inaczej wyglądają nagłówki i wyróżnione fragmenty tekstu – tekst inaczej przelewa się w wątkach i łamach. Aby w dalszym ciągu publikacja tworzyła przejrzystą i spójną całość, trzeba na nowo rozplanować położenie tekstu, zadbać o to, by dobrze komponował się z zakotwiczonymi elementami takimi jak tabele, zdjęcia, rysunki itp. Wychodząc naprzeciw Państwa potrzebom, w naszej firmie zadbaliśmy o to, by móc pełnić kompleksowe usługi DTP. Dlatego też zatrudniamy osoby odpowiedzialne za przygotowanie na komputerze materiałów, które można później powielać – w druku, bądź w internecie. W naszej firmie korzystamy z najpopularniejszych programów graficznych, są wśród nich: Adobe InDesign, Adobe FrameMaker (również w strukturze SGML), Adobe PageMaker, QuarkXPress, Adobe Acrobat+Distiller, Adobe Photoshop, Adobe Illustrator, Corel Draw, AutoCAD czy Microsoft Visio.

InDesign w pracy biura tłumaczeń – Przygotowywanie layoutu dokumentów wielojęzycznych [aktualizacja]
Jednym z najbardziej popularnych narzędzi do komputerowego składu typograficznego tekstu (DTP) w biurze tłumaczeń, o którym pisaliśmy poprzednio, jest program Adobe InDesign. Daje on użytkownikowi ogromne możliwości, trzeba jednak pamiętać, że inaczej pracuje się wtedy, gdy chce się przygotować dokument w jednym języku, niż w sytuacji, w której naszym zadaniem jest opracowanie dokumentu, który będzie funkcjonował w wielu językach.
Gdy projektuje się layout dla dokumentów wielojęzycznych, trzeba z rozwagą zaplanować miejsce na tekst – w tzw. ramkach tekstowych, które funkcjonują podobnie do pól tekstowych w Wordzie. Należy pamiętać, że po przetłumaczeniu tekst zmieni swoją objętość – może się rozszerzyć lub skrócić nawet o 35% (szczególnie w stosunku zachodniego języka niefleksyjnego do np. cyrylicznego). Zmiana objętości tekstu spowoduje modyfikację wyglądu dokumentu – zakotwiczone w nim elementy mogą się przemieścić i w konsekwencji popsuć wygląd publikacji. Konieczne będzie wtedy długotrwałe dopracowywanie dokumentu przez operatora DTP. Aby skrócić czas tej pracy, można zaprojektować layout w odpowiedni sposób.

Kompetencje a kwalifikacje tłumacza: jak oceniać dostawcę usług językowych w projektach B2B (jakość, ryzyko, zgodność)

Ewolucja dużych modeli językowych (LLM) w branży tłumaczeń

Recertyfikacja ISO 17100 – gwarancja jakości usług tłumaczeniowych translax

Tłumaczenia oznaczeń przeciwpożarowych w kontekście norm NFPA

Post-editing (Post-edycja / PE) – niezbędny składnik tłumaczenia maszynowego
Obsługujemy języki
Cookies
Strona wykorzystuje tylko niezbędne ciasteczka techniczne do obsługi sesji i ochrony formularzy; reCAPTCHA i Przelewy24 przetwarzają dane u siebie zgodnie ze swoimi politykami, a my nie zbieramy ani nie profilujemy danych osobowych. Więcej: Polityka prywatności/RODO.



