Biuro tłumaczeń translax – tłumaczenia dla firm
Tag: grafik

13 wskazówek – przygotowanie pliku Word do tłumaczenia
Optymalizacja dokumentów Word do tłumaczenia jest kluczowym krokiem w tłumaczeniu dokumentów. Prawidłowe przygotowanie plików nie tylko przyspiesza proces tłumaczenia, ale także minimalizuje ryzyko błędów i problemów z formatowaniem.
Microsoft Word to jedno z najpopularniejszych narzędzi do tworzenia i edycji dokumentów tekstowych, oferując wiele funkcji wspierających pracę z tekstem. Znajomość tych funkcji oraz ich efektywne wykorzystanie może znacząco wpłynąć na jakość i efektywność tłumaczeń.
W tym artykule znajdziesz praktyczne porady dotyczące m.in. formatowania tekstu, zarządzania zmianami oraz utrzymywania spójności terminologicznej, które pomogą Ci w przygotowaniu dokumentów do tłumaczenia.
1. Używaj oryginalnego pliku Word
Oryginalny plik Word jest kluczowy dla zachowania integralności podczas tłumaczenia. Istnieje kilka powodów, dla których warto używać plików w formacie .docx lub .doc, zamiast konwertować do tych formatów inne pliki takie jak np. PDF.
Dlaczego ważne jest używanie oryginalnych plików
- Zachowanie formatowania: używanie oryginalnego pliku Word gwarantuje, że wszystkie elementy formatowania, takie jak style, nagłówki, akapity, tabele i grafiki, zostają zachowane w nienaruszonym stanie.
- Współpraca z narzędziami CAT (Computer-Assisted Translation): narzędzia CAT są zoptymalizowane pod kątem pracy z formatami .docx i .doc. Oryginalny plik Word umożliwia płynne importowanie tekstu do tych narzędzi oraz automatyczne zachowanie struktury dokumentu.
- Bezpieczeństwo: pliki w formacie .docx są mniej podatne na uszkodzenia niż inne formaty. Są one również łatwiejsze do naprawienia w przypadku problemów technicznych.
Problemy z formatowaniem przy konwersji do PDF
Automatyczna konwersja dokumentów PDF do formatu Word często wiąże się z problemami związanymi z utratą lub zmianą formatowania. Najczęstsze problemy:
- Zmiany układu strony: podczas konwersji mogą wystąpić zmiany w układzie strony, co prowadzi do przesunięcia tekstu i obrazów.
- Problemy z czcionkami: niektóre czcionki mogą nie być prawidłowo osadzone w pliku PDF, co skutkuje ich zastąpieniem przez domyślne czcionki systemowe.
- Brak edytowalności: pliki PDF są zazwyczaj trudniejsze do edycji niż dokumenty Word. Tłumacze muszą korzystać ze specjalistycznego oprogramowania do edycji plików PDF, ręcznie kopiować tekst do nowego dokumentu lub niezbędny jest OCR (szczególnie w przypadku skanów lub plików spłaszczonych/zamienionych na krzywe – np. z Corel lub Adobe Illustrator).
- Kompatybilność z narzędziami CAT: narzędzia wspomagające tłumaczenie mają ograniczoną funkcjonalność przy pracy z plikami PDF w porównaniu do natywnej obsługi plików .docx.
2. Nowy format plików Word (DOCX)
Korzyści z używania formatu DOCX
Format DOCX wprowadzony przez Microsoft w wersji Word 2007 oferuje szereg zalet w porównaniu z wcześniejszym formatem DOC. Przede wszystkim, DOCX jest oparty na otwartym standardzie XML (Extensible Markup Language), co przyczynia się do jego większej elastyczności i wsparcia w różnych aplikacjach, w tym oprogramowaniu tłumaczeniowym.
- Mniejsza wielkość pliku: pliki w formacie DOCX są zazwyczaj mniejsze niż te w formacie DOC. Kompresja danych pozwala na oszczędność miejsca na dysku oraz szybsze przesyłanie plików.
- Lepsza kompatybilność: dzięki XML, format DOCX jest lepiej wspierany przez różnorodne narzędzia do tłumaczeń oraz inne programy biurowe. Zwiększa to niezawodność podczas otwierania i edytowania dokumentów na różnych platformach.
- Mniejsza podatność na uszkodzenia: struktura XML sprawia, że pliki DOCX są mniej narażone na uszkodzenie danych. W przypadku wystąpienia błędów łatwiej jest odzyskać zawartość dokumentu.
- Zaawansowane funkcje: format DOCX obsługuje bardziej zaawansowane funkcje edytorskie, takie jak lepsze wsparcie dla grafik, tabel czy elementów multimedialnych.
Porównanie z formatem DOC
Porównując formaty DOC i DOCX, można zauważyć kilka kluczowych różnic, które wpływają na proces tłumaczenia dokumentów.
Wsparcie dla oprogramowania tłumaczeniowego
Oprogramowanie tłumaczeniowe, takie jak Trados Studio czy memoQ, lepiej radzi sobie z dokumentami w formacie DOCX. Wynika to z:
- Łatwiejszej analizy struktury dokumentu: XML umożliwia bardziej precyzyjną analizę zawartości dokumentu przez narzędzia tłumaczeniowe. Oznacza to lepsze rozpoznawanie segmentów tekstu, co przekłada się na dokładniejsze tłumaczenia.
- Lepszej integracji z pamięciami tłumaczeń (TM): DOCX jest lepiej przystosowany do pracy z pamięciami tłumaczeń oraz glosariuszami, co skraca czas potrzebny na przygotowanie i przetwarzanie dokumentu.
Praktyczne wskazówki
Aby skorzystać ze wszystkich korzyści wynikających z używania formatu DOCX:
- Upewnij się, że wszystkie nowe dokumenty są zapisywane jako .docx. Można ustawić DOCX jako domyślną opcję zapisu w ustawieniach Microsoft Word.
- Konwertuj starsze dokumenty .doc do nowego formatu .docx przy użyciu funkcji „Zapisz jako” dostępnej w menu programu Word.
- Regularnie aktualizuj oprogramowanie Microsoft Office do najnowszej wersji, aby zapewnić maksymalną zgodność i wsparcie dla nowych funkcji edytorskich oraz narzędzi tłumaczeniowych.
Implementacja tych praktyk nie tylko ułatwi proces tłumaczenia dokumentów, ale również zwiększy ich stabilność oraz bezpieczeństwo danych podczas pracy nad nimi.
3. Wyłącz funkcję „Śledź zmiany”
Optymalizacja dokumentów Microsoft Word do tłumaczenia wymaga wyłączenia funkcji Śledź zmiany. Funkcja ta, choć użyteczna podczas procesu redakcyjnego, może wprowadzać komplikacje podczas tłumaczenia dokumentu. Poniżej omówiono kluczowe powody, dla których należy wyłączyć tę funkcję oraz jej wpływ na proces tłumaczenia.
Dlaczego należy wyłączyć śledzenie zmian przed tłumaczeniem?
- Klarowność dokumentu:
-
- Funkcja Śledź zmiany powoduje, że wszystkie zmiany wprowadzane w dokumencie są widoczne jako adnotacje, co może prowadzić do zamieszania dla tłumacza. Takie adnotacje mogą zawierać skreślenia, podkreślenia i komentarze, co utrudnia odczytanie czystego tekstu przeznaczonego do tłumaczenia.
- Tłumacz musi mieć dostęp do najbardziej aktualnej i ostatecznej wersji tekstu bez konieczności przeglądania historii zmian.
- Złożoność techniczna:
-
- Pliki z włączoną funkcją Śledź zmiany mogą być trudniejsze do przetworzenia przez narzędzia CAT (Computer-Assisted Translation). Narzędzia te korzystają z algorytmów przetwarzających tekst w celu automatycznego dostosowania segmentów tłumaczeń i zarządzania pamięcią tłumaczeniową.
- Śledzone zmiany mogą zakłócać działanie tych algorytmów, co prowadzi do błędów i niekompletności tłumaczeń.
- Efektywność pracy tłumacza:
-
- Obecność wielu zmian może spowolnić pracę tłumacza, który musi najpierw zrozumieć kontekst każdej zmiany przed przystąpieniem do faktycznego tłumaczenia.
- Wyłączenie tej funkcji pozwala na skupienie się na rzeczywistym tekście przeznaczonym do przekładu, co przyspiesza cały proces.
Jak wyłączyć funkcję Śledź zmiany
- Otwórz dokument w Microsoft Word.
- Przejdź do zakładki Recenzja.
- W sekcji Śledzenie kliknij przycisk Śledź zmiany, aby wyłączyć tę funkcję.
- Następnie zaakceptuj lub odrzuć wszystkie zmiany, aby wyczyścić dokument.
- Teraz możesz przekazać czysty tekst tłumaczowi.
- W przypadku dalszych zmian lub uwag, zaleca się powtórne włączenie funkcji Śledź zmiany i kontynuowanie procesu edycji i recenzji.
4. Zmiany i komentarze
Akceptacja zmian
W procesie przygotowywania dokumentów do tłumaczenia niezwykle istotnym krokiem jest akceptacja lub odrzucenie wszystkich zmian wprowadzonych za pomocą funkcji „Śledź zmiany”. Pozostawienie niezaakceptowanych zmian może prowadzić do licznych problemów w trakcie tłumaczenia, takich jak:
- Niejasności dla tłumaczy: tłumacz może nie być pewien, czy powinien tłumaczyć oryginalny tekst, czy zmodyfikowaną wersję.
- Problemy z formatowaniem: niezaakceptowane zmiany mogą wpłynąć na układ i formatowanie dokumentu, co z kolei może prowadzić do błędów w tłumaczeniu.
Aby rozwiązać te problemy, należy przejrzeć wszystkie zmiany w dokumencie i podjąć decyzję o ich akceptacji lub odrzuceniu. Proces ten można przeprowadzić w kilku krokach:
- W programie Microsoft Word kliknij zakładkę „Recenzja”, aby uzyskać dostęp do narzędzi związanych ze śledzeniem zmian.
- Przejrzyj każdą zaproponowaną zmianę w dokumencie. Można to zrobić za pomocą przycisków „Następna” i „Poprzednia”, aby przeskakiwać między zmianami.
- Zaakceptuj zmiany, które są poprawne i zgodne z ostateczną wersją dokumentu. Odrzuć te, które nie są potrzebne lub są błędne.
Komentarze w dokumentach
Komentarze w dokumentach Word są często używane do przekazywania dodatkowych informacji, wyjaśnień lub sugestii dotyczących treści. Choć komentarze te mogą być bardzo pomocne podczas tworzenia dokumentu, mogą one również stanowić źródło niejasności dla tłumaczy, jeżeli pozostaną nierozwiązane przed rozpoczęciem procesu tłumaczenia.
Kilka powodów, dla których warto rozwiązać komentarze przed wysłaniem dokumentu do tłumaczenia:
- Usunięcie lub rozwiązanie komentarzy sprawia, że dokument staje się bardziej przejrzysty dla tłumacza, co pozwala mu skupić się na właściwej treści bez konieczności interpretowania dodatkowych uwag.
- Komentarze mogą zawierać sugestie lub pytania dotyczące treści, które mogły już zostać uwzględnione w finalnej wersji tekstu. Pozostawienie ich bez odpowiedzi może prowadzić do nieporozumień i błędów w tłumaczeniu.
Aby usunąć komentarze z dokumentu Word:
- Przejrzyj wszystkie komentarze za pomocą zakładki „Recenzja”. Narzędzie do przeglądania komentarzy pozwala na szybkie przechodzenie między poszczególnymi uwagami.
- Jeśli komentarz zawiera informacje ważne dla tłumacza (np. kontekst kulturowy), można dodać te informacje bezpośrednio do głównego tekstu dokumentu lub jako notatkę informacyjną obok odpowiedniego fragmentu tekstu. Komentarze czysto redakcyjne lub techniczne należy usunąć.
Przykład: Jeśli istnieje komentarz dotyczący specyficznego terminu technicznego, najlepiej jest wyjaśnić ten termin bezpośrednio w tekście głównym bądź za pomocą przypisu.
5. Używaj jednego języka w dokumencie
Mieszanie kilku języków w jednym dokumencie może prowadzić do komplikacji podczas procesu tłumaczenia. Przede wszystkim utrudnia to pracę tłumaczom, którzy muszą rozpoznać i oddzielić poszczególne fragmenty tekstu napisane w różnych językach. Ponadto może to prowadzić do błędów w automatycznych narzędziach tłumaczeniowych, które mogą nieprawidłowo zidentyfikować język źródłowy.
Problemy związane z mieszaniem języków obejmują:
- Narzędzia tłumaczeniowe mogą mieć trudności z prawidłowym rozpoznaniem języka źródłowego, co może skutkować niepoprawnymi tłumaczeniami.
- Mieszanie języków może prowadzić do problemów z formatowaniem, takich jak niewłaściwe zastosowanie stylów czy problemy z układem tekstu.
- Tłumacze mogą przeoczyć fragmenty tekstu napisane w innym języku, co zwiększa ryzyko popełnienia błędów.
Aby uniknąć powyższych problemów, zaleca się tworzenie osobnych dokumentów dla każdego używanego języka. Proces ten jest stosunkowo prosty i znacząco ułatwia pracę zarówno tłumaczom, jak i użytkownikom narzędzi tłumaczeniowych.
- Rozdziel zawartość dokumentu na sekcje według używanych języków. Każda sekcja powinna być niezależnym blokiem tekstu napisanym wyłącznie w jednym języku.
- Skopiuj każdą sekcję do nowego dokumentu Microsoft Word. Upewnij się, że każdy nowy dokument zawiera tylko jedną wersję językową.
- Nadaj nowym dokumentom nazwy zgodne z ustalonymi kodami językowymi i numerami wersji (np.: Dokument_EN_v1.docx dla angielskiej wersji pierwszej). Takie nazewnictwo ułatwia identyfikację i zarządzanie plikami.
- Upewnij się, że ustawienia językowe programu Word są poprawnie skonfigurowane dla każdego nowego dokumentu (np.: sprawdzanie pisowni i gramatyki).
Przykład:
Jeśli masz oryginalny dokument zawierający tekst po polsku i angielsku, utwórz dwa oddzielne dokumenty:
- Dokument_PL_v1.docx — zawierający tylko polski tekst
- Dokument_EN_v1.docx — zawierający tylko angielski tekst
Takie podejście pozwala na bardziej precyzyjne i efektywne zarządzanie procesem tłumaczenia oraz minimalizuje ryzyko błędów wynikających z mieszania różnych języków.
Stosowanie strategii „jeden język na dokument” przynosi wiele korzyści:
- Tworzenie osobnych dokumentów dla każdego języka pozwala na lepsze zarządzanie projektem i ułatwia kontrolę nad postępem prac tłumaczeniowych.
- Tłumacze mogą skupić się na jednym języku, co zmniejsza ryzyko błędów i przyspiesza cały proces.
- Jasno podzielone treści umożliwiają szybsze przygotowanie materiałów do tłumaczenia oraz ich późniejsze przetwarzanie przez narzędzia CAT (Computer-Assisted Translation).
- Jednojęzykowe dokumenty pozwalają na precyzyjniejsze dostosowanie stylu oraz tonu przekazu do specyfiki danego rynku docelowego.
Implementacja zasady stosowania jednego języka na dokument zdecydowanie ułatwia proces tłumaczenia oraz przyczynia się do uzyskania bardziej spójnych i wysokiej jakości efektów.
6. Nazwij dokumenty z kodami językowymi i numerami wersji
Właściwe nazewnictwo dokumentów jest kluczowym elementem optymalizacji plików Microsoft Word do tłumaczenia. Przejrzyste nazwy dokumentów pomagają zidentyfikować ich zawartość, wersję oraz język, co znacząco ułatwia pracę tłumaczom i osobom zarządzającym projektami.
Jak nadawać przejrzyste nazwy dokumentom
- Kody językowe: używanie kodów językowych w nazwach plików to praktyka, która umożliwia natychmiastowe rozpoznanie języka dokumentu. Standardowe kody językowe opierają się na normie ISO 639-1, która przypisuje dwuliterowe skróty dla poszczególnych języków (np. EN dla angielskiego, DE dla niemieckiego, FR dla francuskiego). Uwaga: pamiętaj, że oznaczenia języków często różnią się od oznaczeń krajów! Np. język ukraiński to UK, a nie UA. Czeski = CS, a nie CZ itd.
- Numeracja wersji dokumentów: numeracja wersji jest równie ważna, jak kody językowe. Pomaga śledzić zmiany w dokumencie i zapobiega problemom związanym z używaniem nieaktualnych wersji. Popularnym systemem jest użycie ciągów liczbowych oddzielonych kropkami (np. v1.0, v2.1).
Przykłady nazw z kodami językowymi
Poniżej znajdują się przykłady nazw plików zgodnych z zasadami używania kodów językowych oraz numeracji wersji:
- Dokumenty marketingowe:
- Marketing_Plan_EN_v1.0.docx: Plan marketingowy w języku angielskim, wersja 1.0.
- Marketing_Plan_DE_v2.3.docx: Plan marketingowy w języku niemieckim, wersja 2.3.
- Marketing_Plan_FR_v1.1.docx: Plan marketingowy w języku francuskim, wersja 1.1.
- Dokumenty techniczne:
- Technical_Specifications_EN_v3.2.docx: Specyfikacje techniczne w języku angielskim, wersja 3.2.
- Technical_Specifications_ES_v4.0.docx: Specyfikacje techniczne w języku hiszpańskim, wersja 4.0.
- Technical_Specifications_IT_v2.5.docx: Specyfikacje techniczne w języku włoskim, wersja 2.5.
- Instrukcje użytkownika:
- User_Manual_EN_v5.0.docx: Instrukcja użytkownika w języku angielskim, wersja 5.0.
- User_Manual_JA_v4.1.docx: Instrukcja użytkownika w języku japońskim, wersja 4.1.
- User_Manual_RU_v3.3.docx: Instrukcja użytkownika w języku rosyjskim, wersja 3.3.
Nazewnictwo dokumentów powinno być jasne i precyzyjne, aby unikać nieporozumień i błędów podczas procesu tłumaczenia:
- Używanie jednoznacznych kodów i numeracji umożliwia natychmiastową identyfikację treści dokumentu bez potrzeby otwierania go.
- Dokładne nazewnictwo pozwala na łatwe śledzenie zmian i aktualizacji dokumentu oraz zapewnia spójność pomiędzy różnymi wersjami.
Zalecenia dotyczące formatowania nazw
Aby osiągnąć najlepsze rezultaty przy nadawaniu nazw plikom Microsoft Word przeznaczonym do tłumaczenia:
- Unikaj długich i skomplikowanych nazw – prostota sprzyja czytelności.
- Stosuj jednolite zasady nazewnictwa we wszystkich projektach – spójność pomaga utrzymać porządek.
- Uwzględnij datę ostatniej modyfikacji – opcjonalnie można dodać datę jako dodatkowy wskaźnik aktualności (np., Marketing_Plan_EN_v1.0_20231001.docx). Warto rozważyć dodanie daty na początku nazwy pliku, co pozwoli lepiej sortować pliki.
Zastosowanie powyższych wskazówek pomoże zoptymalizować proces tłumaczenia dokumentów Microsoft Word poprzez ułatwienie identyfikacji i zarządzania plikami na każdym etapie pracy.
7. Pokaż ukryte znaki i umiejętnie podziel linie
Ukryte znaki w Wordzie
Znaki ukryte to elementy formatowania, które nie są widoczne w trybie normalnego przeglądania dokumentu, ale mają kluczowe znaczenie dla jego struktury. Aktywując wyświetlanie ukrytych znaków, można zobaczyć m.in.:
- Znaki końca akapitu (
¶) - Znaki tabulacji (
→) - Spacje (
·) - Twarde spacje (°)
- Znaki podziałów stron/sekcji (
----------)
Aby pokazać ukryte znaki, przejdź do karty Narzędzia główne i kliknij ikonę ¶ w grupie Akapit.
Identyfikacja problemów z formatowaniem
Wyświetlenie ukrytych znaków pozwala na szybkie zidentyfikowanie problemów związanych z formatowaniem dokumentu. Przykładowo:
- Podwójne/wielokrotne spacje: mogą nie być widoczne bez włączenia ukrytych znaków, a ich usunięcie jest kluczowe przed przystąpieniem do tłumaczenia.
- Nieprawidłowe użycie tabulatorów: zamiast stosowania tabulatorów do wyrównywania tekstu, lepiej używać tabel lub stylów akapitowych z odpowiednimi wcięciami.
- Dodatkowe znaki końca akapitu: często spotykane na końcu linii mogą powodować niepotrzebne przerwy w tekście.
- Mieszanie twardych i miękkich „powrotów”: używanie różnych typów powrotów karetki może zaburzać strukturę dokumentu.
Organizacja tekstu za pomocą twardych i miękkich enterów
Prawidłowa organizacja tekstu wymaga zrozumienia różnicy między twardymi a miękkimi powrotami linii.
Twarde entery (Enter)
Twardy powrót (Enter) tworzy nowy akapit. Jest to standardowy sposób na oddzielanie bloków tekstu, który powinien być stosowany tam, gdzie rozpoczyna się nowa myśl lub sekcja. Twarde powroty są oznaczone symbolem ¶.
Miękkie entery (Shift + Enter)
Miękki powrót (Shift + Enter) tworzy nową linię wewnątrz tego samego akapitu. Powinien być stosowany do łamania linii bez rozpoczynania nowego akapitu, co jest przydatne np. przy dodawaniu nowych wierszy do listy lub dzieleniu długich linijek tekstu. Należy na niego uważać w przypadku tekstu justowanego!
Przykład zastosowania:
Wprowadzenie do tłumaczeń:
- Punkt pierwszy
- Podpunkt pierwszy
- Podpunkt drugi
W powyższym przykładzie zastosowanie miękkiego powrotu (Shift + Enter) po „Punkt pierwszy” pozwala na kontynuację formatowania listy bez rozpoczynania nowego akapitu rozpoczynanego kolejnym numerem porządkowym. Wstawienie twardego entera rozpocznie nowy akapit, dodając kolejną liczbę lub punktor (ang. bullet).
Korzyści dla tłumaczy
Pokazanie ukrytych znaków oraz prawidłowe użycie twardych i miękkich powrotów znacząco ułatwia pracę tłumaczom:
- Jasność struktury dokumentu: tłumacze mogą łatwo zrozumieć, jak struktura dokumentu została zaplanowana i jakie są zamierzenia autora względem formatowania.
- Uniknięcie nieporozumień: widoczność ukrytych znaków pomaga unikać błędnych interpretacji dotyczących przerw między sekcjami czy wyrównania tekstu.
8. Formatuj tekst za pomocą stylów
Style w Wordzie stanowią jedno z najważniejszych narzędzi umożliwiających utrzymanie jednolitości formatowania. Używanie predefiniowanych stylów zamiast ręcznego formatowania przynosi szereg korzyści.
Korzyści z używania predefiniowanych stylów
- Stosowanie stylów zapewnia spójność w całym dokumencie. Oznacza to, że wszystkie elementy takie jak nagłówki, akapity czy cytaty będą miały identyczne formatowanie, co znacznie ułatwia czytanie i tłumaczenie tekstu.
- Zmiana formatu jednego stylu automatycznie aktualizuje wszystkie elementy korzystające z tego stylu. Na przykład zmiana wielkości czcionki dla stylu „Nagłówek 1” wpłynie na wszystkie nagłówki pierwszego poziomu w dokumencie.
- Stylom można przypisać skróty klawiszowe, co przyspiesza proces edycji dokumentu. W rezultacie unika się czasochłonnego ręcznego formatowania każdego elementu.
Zastosowanie stylów nagłówków
Użycie stylów nagłówków jest kluczowe dla czytelności i dokładności tłumaczeń. Nagłówki pomagają w organizacji treści oraz stanowią ważny punkt odniesienia dla tłumaczy.
- Nagłówki tworzą logiczną strukturę dokumentu, co ułatwia nawigację zarówno podczas tworzenia, jak i tłumaczenia dokumentu.
- Dzięki zastosowaniu stylów nagłówków możliwe jest automatyczne generowanie spisów treści. Narzędzie to jest niezwykle użyteczne dla tłumaczy, którzy mogą szybko przejść do interesujących ich sekcji.
- Stylizowane nagłówki są łatwiejsze do zauważenia i zrozumienia przez odbiorców, co zwiększa efektywność komunikacyjną dokumentu.
Znaczenie zachowania spójności w nagłówkach
Niepomijanie poziomów nagłówków jest istotne dla dostępności treści i poprawnej interpretacji dokumentu przez narzędzia tłumaczeniowe.
- Zachowanie kolejności poziomów nagłówków (Nagłówek 1, Nagłówek 2 itd.) zapewnia logiczny i spójny układ treści. Pomijanie poziomów może wprowadzić chaos i utrudnić pracę tłumaczom.
- Dla osób korzystających z czytników ekranowych lub innych technologii wspomagających, spójna struktura nagłówków jest kluczowa do poprawnej nawigacji po dokumencie.
- Struktura oparta na stylach umożliwia tłumaczom lepsze zrozumienie kontekstu poszczególnych części tekstu. Przykładowo, rozróżnienie między głównymi sekcjami a podsekcjami pozwala na dokładniejsze tłumaczenie.
Wykorzystanie takich funkcji jak style znakowe czy akapitowe również przyczynia się do utrzymania jednolitości formatowania oraz ułatwia pracę nad edytowaniem i tłumaczeniem dokumentu. Style znakowe są szczególnie użyteczne dla terminologii specjalistycznej lub fragmentów tekstu wymagających specyficznego formatowania.
Podsumowując:
- Stosowanie stylów zapewnia jednolitość formatowania oraz łatwość aktualizacji.
- Nagłówki i akapity ułatwiają organizację oraz nawigację po dokumencie.
- Spójność poziomów nagłówków kluczowa dla dostępności treści oraz precyzyjnego tłumaczenia.
Utrzymywanie konsekwentnego formatowania przy użyciu stylów w Wordzie nie tylko poprawia jakość ostatecznego dokumentu, ale także znacząco ułatwia jego przetwarzanie przez narzędzia tłumaczeniowe i samych tłumaczy.
9. Używaj też stylów znakowych
Tworzenie stylów znakowych jest kluczowym elementem, który ułatwia szybkie dostosowywanie treści. Style znakowe to zdefiniowane zestawy formatowania, które można stosować do pojedynczych słów lub fraz w dokumencie. Dzięki nim można łatwo wyróżniać specyficzne terminy techniczne, nazwy własne czy inne kluczowe elementy tekstu.
Jak stworzyć styl znakowy?
- Otwórz zakładkę „Style” w menu głównym programu Microsoft Word.
- Kliknij przycisk „Nowy styl” i wybierz opcję „Styl znakowy”.
- Nadaj nazwę swojemu stylowi, np. „Termin techniczny”.
- Zdefiniuj formatowanie: wybierz czcionkę, rozmiar, kolor oraz inne atrybuty, które mają być stosowane dla tego stylu.
- Zatwierdź zmiany, klikając „OK”.
Przykład zastosowania: jeżeli dokument zawiera wiele terminów takich jak „API”, „SaaS” czy „IoT”, można stworzyć styl znakowy o nazwie „Termin techniczny”, który będzie je wyróżniał za pomocą kursywy i niebieskiego koloru.
Pamiętaj: dobrze zaplanowany dokument to podstawa efektywnego tłumaczenia!
10. Zachowuj prostotę formatowania, ogranicz użycie pól tekstowych, zapewnij informacje kontekstowe.
Proste Formatowanie
Minimalizacja skomplikowanego formatowania w dokumentach Microsoft Word jest kluczowa z kilku powodów:
- Używanie zbyt wielu różnych stylów, czcionek, kolorów lub innych elementów formatowania może prowadzić do chaosu wizualnego. Dokumenty takie są trudniejsze do odczytania i przetworzenia zarówno przez ludzi, jak i oprogramowanie tłumaczeniowe.
- Skomplikowane wzory mogą nie być dobrze obsługiwane przez narzędzia CAT (Computer-Assisted Translation), co może prowadzić do błędów podczas tłumaczenia.
- Prostsze formatowanie ułatwia modyfikacje i aktualizacje dokumentów bez ryzyka uszkodzenia ich struktury.
Przykład prostego formatowania:
Nagłówek 1
Nagłówek 2
Tekst akapitu z jednolitym stylem czcionki.
Unikanie pól tekstowych
Pola tekstowe mogą stanowić poważne wyzwanie w procesie tłumaczenia:
- Tekst umieszczony w polach tekstowych może być trudniej dostępny dla narzędzi tłumaczeniowych, co może prowadzić do pominięcia fragmentów tekstu.
- Podczas tłumaczenia długość tekstu może się zmieniać. Pola tekstowe o stałych rozmiarach mogą nie pomieścić przetłumaczonych treści, co wymaga dodatkowej pracy przy dostosowaniu układu dokumentu.
Alternatywą dla pól tekstowych jest używanie tabeli lub formatowania za pomocą stylów akapitów.
Zapewnienie informacji kontekstowych
Notatki i komentarze w dokumentach Word odgrywają istotną rolę w dostarczaniu kontekstu dla tłumaczy:
- Komentarze mogą dostarczyć dodatkowych informacji na temat specyficznych terminów, skrótów lub kulturowych odniesień, które mogą być trudne do zrozumienia bez odpowiedniego kontekstu.
- Notatki mogą zawierać wskazówki dotyczące preferowanego stylu tłumaczenia, terminologii czy tonacji języka.
11. Utrzymuj spójną terminologię
Jak stworzyć glosariusz?
Stworzenie i utrzymanie glosariusza jest kluczowe dla zapewnienia spójności w tłumaczonych dokumentach. Glosariusz powinien zawierać specyficzne terminy używane w danym kontekście oraz ich odpowiedniki w docelowych językach. W ten sposób tłumacze mają dostęp do predefiniowanych terminów, co eliminuje niejednoznaczność i umożliwia zachowanie jednolitego stylu.
Aby tłumaczenie było spójne, terminologia używana w dokumencie źródłowym również musi być spójna!
Kroki do stworzenia efektywnego glosariusza:
- Identyfikacja kluczowych terminów: rozpocznij od zidentyfikowania terminów technicznych, branżowych oraz specyficznych dla organizacji.
- Konsultacje z ekspertami: skonsultuj się ze specjalistami dziedzinowymi, aby upewnić się, że wybrane terminy są poprawne i aktualne.
- Weryfikacja tłumaczeń: zadbaj o to, aby przetłumaczone terminy były zatwierdzone przez native speakerów lub certyfikowanych tłumaczy.
- Ciągła aktualizacja: regularnie aktualizuj glosariusz, aby uwzględniał nowe terminy oraz zmiany w istniejących definicjach.
Gdy już masz glosariusz
Sprawdzenie spójności terminologii użytej w dokumencie źródłowym z glosariuszem jest kluczowe dla zapewnienia jednolitości i poprawności tłumaczenia. Każdy rodzaj tekstu ma swoje specyficzne wymagania:
- Teksty marketingowe: takie dokumenty często korzystają z synonimów, aby uniknąć monotonii i przyciągnąć uwagę odbiorców. W przypadku tłumaczeń marketingowych ważne jest, aby zachować kreatywność, ale jednocześnie dbać o to, aby kluczowe terminy były zgodne z glosariuszem.
- Teksty techniczne: w przeciwieństwie do tekstów marketingowych, dokumenty techniczne wymagają dokładnych powtórzeń. Każda fraza techniczna musi być konsekwentnie używana zgodnie z definicjami zawartymi w glosariuszu. To zapewnia precyzję i jednoznaczność, co jest niezwykle istotne w dokumentacji technicznej.
Korzyści ze spójnej terminologii
- Jasność komunikacji: spójna terminologia eliminuje ryzyko nieporozumień i błędnych interpretacji nie tylko w kontekście komunikacji z biurem tłumaczeń, ale także wewnątrz firmy.
- Profesjonalizm: zachowanie jednolitego stylu i słownictwa podnosi jakość oraz profesjonalizm przetłumaczonych dokumentów.
- Efektywność: przyspiesza proces tłumaczenia poprzez zmniejszenie liczby koniecznych poprawek oraz konsultacji.
Dążenie do spójności terminologicznej to fundament profesjonalnego dokumentu oraz jego tłumaczenia.
12. Sprawdź ustawienia językowe
Ustawienia językowe w Microsoft Word nie tylko wpływają na sprawdzanie pisowni i gramatyki, ale także na rozpoznawanie kontekstu językowego dokumentu. Poprawne skonfigurowanie tych ustawień jest fundamentalne dla uniknięcia błędów automatycznej korekty oraz zapewnienia poprawności językowej.
Kluczowe aspekty ustawień językowych:
- Przejdź do zakładki Recenzja i wybierz opcję Język, a następnie Ustaw język sprawdzania. Upewnij się, że wybrany język odpowiada rzeczywistej treści dokumentu.
- Aktywuj funkcje sprawdzania pisowni i gramatyki dla wybranego języka, co pomoże wykryć ewentualne błędy przed wysłaniem dokumentu do tłumaczenia.
- Upewnij się, że wszystkie segmenty tekstu są skonfigurowane pod kątem jednego języka. Mieszanie kilku języków może prowadzić do problemów z automatycznym rozpoznawaniem błędów.
13. Optymalizuj tabele
Aby uniknąć błędów i zapewnić poprawne formatowanie, warto zwrócić uwagę na kilka kluczowych aspektów:
- Unikaj skomplikowanych układów tabel z wieloma scalonymi komórkami. Proste tabele są łatwiejsze do przetłumaczenia i zmniejszają ryzyko wystąpienia błędów.
- Upewnij się, że wszystkie komórki mają ten sam styl i format. Jednolite formatowanie ułatwia pracę tłumaczowi i zwiększa spójność dokumentu.
- Zredukowanie liczby grafik, ikon czy innych elementów wizualnych w tabelach może znacznie uprościć proces tłumaczenia. Skoncentruj się na przejrzystości i funkcjonalności tabel.
- Starannie zaplanuj rozmieszczenie treści w tabeli, aby każdy segment informacji był czytelny i logicznie uszeregowany. Pomaga to uniknąć dezorientacji i ułatwia późniejsze modyfikacje.
Testuj tabele przed wysłaniem
Przed wysłaniem dokumentu do tłumacza:
- Upewnij się, że wszystkie elementy tabel są prawidłowo wyświetlane na różnych urządzeniach i wersjach oprogramowania.
- Przejrzyj tabele pod kątem błędów merytorycznych oraz ewentualnych literówek.
- Jeśli to możliwe, przetestuj tłumaczenie fragmentu tabeli, aby upewnić się, że struktura pozostaje nienaruszona po zmianie języka.
Pamiętaj, że starannie przygotowane tabele nie tylko ułatwiają pracę tłumaczowi, ale również wpływają na ostateczną jakość przetłumaczonego dokumentu.
Podsumowanie
Podsumowując, świadoma komunikacja i współpraca z tłumaczem są kluczowe dla osiągnięcia wysokiej jakości tłumaczenia. Pamiętaj o tym, kiedy przystępujesz do projektu tłumaczenia. Dobre tłumaczenie ma swoje źródło w dobrze zaplanowanym, zaprojektowanym i stworzonym dokumencie. Przede wszystkim, używaj oryginalnych plików Word i korzystaj z formatu DOCX. Ważne jest również wyłączenie funkcji „Śledź zmiany” przed rozpoczęciem tłumaczenia, co zapobiega potencjalnym problemom i nieporozumieniom związanym z zatwierdzaniem zmian oraz komentarzy w dokumentach.
Stosuj jeden język w całym dokumencie oraz nadawaj przejrzyste nazwy plikom, uwzględniając kody językowe i numery wersji. Pomaga to w organizacji pracy i łatwiejszym zarządzaniu różnymi wersjami dokumentów. Dodatkowo opracowuj dokument źródłowy z włączonymi znakami ukrytymi, co pozwoli na umiejętne dzielenie linii za pomocą twardych i miękkich enterów.
Formatowanie tekstu za pomocą predefiniowanych stylów nie tylko zachowuje spójność wizualną dokumentu, ale także umożliwia łatwiejsze nawigowanie po jego zawartości. Zastosowanie stylów znakowych oraz ograniczenie zbędnego formatowania, takiego jak pola tekstowe czy niepotrzebne grafiki w tabelach, również przyczynia się do prostoty i klarowności dokumentu.
Utrzymywanie spójnej terminologii poprzez stworzenie glosariusza oraz regularna kontrola ustawień językowych to kolejne kroki ku zapewnieniu wysokiej jakości tłumaczenia. Optymalizacja tabel, testowanie ich przed wysłaniem oraz dokładne planowanie rozmieszczenia treści pomagają uniknąć dezorientacji i ułatwiają późniejsze modyfikacje.
Wszystkie te działania wspomagają proces tłumaczenia, czyniąc go bardziej efektywnym i mniej narażonym na błędy. Przejrzystość, funkcjonalność oraz staranne przygotowanie każdego elementu dokumentu mają bezpośredni wpływ na jakość końcowego przekładu. Dzięki temu ostateczny efekt pracy będzie zgodny z oczekiwaniami zarówno Twoimi, jak i odbiorców przetłumaczonego tekstu.
Kontakt

Profesjonalny OCR dokumentów: przewodnik dla tłumaczy i grafików
OCR w tłumaczeniach
Optyczne rozpoznawanie znaków (OCR) stało się nieodzownym narzędziem w arsenale współczesnych specjalistów branży tłumaczeniowej i projektowej. OCR umożliwia przekształcenie drukowanego, nieedytowalnego tekstu (np. ze skanu, zdjęcia lub tekstu zamienionego na krzywe) w format cyfrowy, edytowalny i przeszukiwalny poprzez konwersję wyglądu liter w tekst zakodowany maszynowo. Zupełnie, jak czowiek, który spogląda na stronę książki i przepisuje tekst do Worda.
Spis treści:
- Rodzaje OCR
- Transdoc z FineReader
- Draft_OCR – proste odwzorowanie
- Pełne odwzorowanie graficzne
- Korzyści płynące z doskonałego OCR
- Najlepsze praktyki OCR
- Optymalizacja plików DOCX dla narzędzi CAT
- Kluczowe wnioski
OCR stał się nieocenionym narzędziem dla tłumaczy. Niezależnie od typu dokumentu FineReader (podstawowe narzędzie do OCR) skutecznie skanuje i wyodrębnia tekst, usprawniając proces tłumaczenia. Czytając o FineReaderze (dla uproszczenia) zawsze należy przez to rozumieć Edytor OCR, który jest osobną aplikacją wchodzącą w skład programu FineReader. Należy jednak pamiętać, że OCR, mimo swojej skuteczności, nie jest bezbłędny. Drobne pomyłki w rozpoznawaniu mogą się zdarzać, dlatego konieczna jest uważna weryfikacja wyników.
OCR w projektowaniu graficznym
Graficy również docenili potencjał OCR, gdyż umożliwia szybkie wyodrębnianie tekstu z obrazów i manipulację nim w projektach. FineReader nie tylko przyspiesza pracę, ale również zwiększa precyzję (w porównaniu do ręcznego przepisywania). Graficy mogą skanować dokumenty, dostosowywać układ i ponownie wykorzystywać treść w spójny sposób, często bez kompromisów w zakresie oryginalnych elementów projektu.
Tłumacz, grafik, specjalista DTP?
OCR, niegdyś domena wąskiej grupy specjalistów DTP, stała się integralną częścią codziennej praktyki wielu profesjonalistów z sektora językowego.
Na rynku pojawiła się również grupa specjalistów skoncentrowanych wyłącznie na OCR, których umiejętności można postrzegać jako wyspecjalizowany, ale wąski wycinek kompetencji pełnoprawnego specjalisty DTP. Co więcej, sami tłumacze coraz częściej sięgają po narzędzia OCR, wykorzystując je zarówno na własne potrzeby, jak i wspierając tym swoich współpracowników.
Takie połączenie kompetencji sprawia, że granice między rolami zawodowymi zacierają się. W kontekście niniejszego artykułu „grafik” będzie stosowany wymiennie z „tłumaczem”, odnosząc się do każdego profesjonalisty, który w swojej pracy wykorzystuje technologię OCR.
Rodzaje OCR
Optyczne rozpoznawanie znaków oferuje wiele rozwiązań, z których każde ma swoje unikalne zalety i zastosowania. W OCR mamy do czynienia z różnorodnością opcji dostosowanych do specyficznych potrzeb użytkowników i projektów.
Transdoc: tabela dwujęzyczna
Transdoc to plik składający się z dwujęzycznej tabeli, idealny dla tłumaczy pracujących nad dokumentami wymagającymi zestawienia tekstów w dwóch językach. Główną zaletą takiego przygotowania pliku do tłumaczenia jest zdolność do generowania tabelarycznych reprezentacji treści w różnych językach, zachowując przy tym formatowanie i kontekst. Transdoc nie tylko umożliwia dokładne odwzorowanie tekstu w obu językach, ale również zapewnia, że oba teksty są starannie ułożone obok siebie. Funkcjonalność ta znacząco ułatwia proces tłumaczenia, pozwalając tłumaczom na łatwe porównywanie wersji źródłowej i docelowej podczas ostatniej kontroli jakości. Zwykle wykorzystuje się Transdoc, gdy klient końcowy życzy sobie przygotowania tłumaczenia w wersji dwujęzycznej (np. umowy) lub grafik klienta zajmie się składem DTP tłumaczenia, więc płacenie za odwzorowanie graficzne mijałoby się z celem.
Proste odwzorowanie: keep it simple
Proste odtworzenie układu graficznego to bezpośrednie i konkretne podejście do OCR, idealne do pracy z dokumentami, które nie wymagają oddania skomplikowanego formatowania. Metoda ta skupia się na dokładnym wyodrębnieniu tekstu, bez uwzględniania elementów takich jak czcionki, kolory czy złożone układy.
Przykładem zastosowania prostego odtworzenia może być konwersja protokołu ze spotkania z formatu papierowego na edytowalny. W tym przypadku kluczowe jest zapewnienie, że każda informacja zostanie precyzyjnie przetłumaczona. Chociaż metoda ta wydaje się prosta, wymaga dokładności. W tym przypadku odwzorowuje się oryginalne teksty z zachowaniem logicznego porządku oraz niezbędnych przepływów wraz z formatowaniem lokalnym takim, jak pogrubienia, podkreślenia, indeksy, pismo kursywne (i inne oczywiste wyróżnienia wewnątrz zdania, które mają zastosowanie funkcjonalne). Jeśli oryginalny dokument jest wielokolumnowy, zawiera różne fonty i ich wielkości, marginesy itd., to takie elementy nie zostaną oddane. Prosty OCR zapewnia określony standard przygotowania np. Format A4, Arial dla oryginalnych tekstów bezszeryfowych i Times New Roman dla szeryfowych. Nagłówki/tytuły wielkości 16 punktów, a reszta tekstów 12 punktów. Stałe marginesy 2,5 cm z każdej strony itd.
Pełne odwzorowanie układu i formatowania
Pełne odwzorowanie pozwala na dokładne odtworzenie wyglądu dokumentów. Metoda ta zachowuje nie tylko tekst, ale również style czcionek (jeśli są korporacyjne lub komercyjne, to klient musi je dostarczyć), rozmieszczenie obrazów i ogólny układ dokumentu. W zasadzie odwzorowanie pełne można nazwać roboczo odbudowaniem/odtworzeniem oryginalnego dokumentu.
W przypadku odwzorowania katalogu OCR musi wyciągnąć zarówno opisy produktów, jak i elementy wizualne, tworząc nowy dokument, który wygląda jak podobnie do oryginału.
Oczywiście często jest tak, że elementy graficzne trzeba ekstrahować ręcznie np. za pomocą Acrobata, Photoshopa, czy Illustratora, by stworzyć zasoby na potrzeby pełnego odwzorowania. Pamiętajmy, że pełne odwzorowanie nie kończy się na Wordzie. Często przygotowujemy tak zwany nowy oryginał w InDesign, by stworzyć dokument, który będzie miał „nowe” życie i potencjał rozwojowy (aktualizacyjny). W tym przypadku odwzorowujemy wszystko od formatu strony, przez fonty, kolory, marginesy, wcięcia, tabulatory, style, automatyzacje (odnośniki, spisy tabel, ilustracji, treści, indeksy…), grafiki itd.
Wybór scenariusza
Wybór odpowiedniego rodzaju OCR zależy od specyfiki projektu i potrzeb. Kluczowe pytania, które należy sobie zadać, to:
- Czy dokument jest głównie tekstowy, czy ma złożony projekt graficzny?
- Czy wymagana jest dwujęzyczna forma?
- Jak istotne są elementy wizualne dla zrozumienia treści?
- Jakie są wymagania odbiorców docelowych?
- Jakie są wymagania klienta końcowego?
- W jaki sposób będzie tłumaczony dany dokument (w CAT, czy bez CAT)?
- Czy po tłumaczeniu będzie wykonywany skład DTP i przygotowanie do druku, czy jest to dokument wewnętrzny?
Przy wyborze typu OCR kluczowe jest zrozumienie nie tylko technicznych aspektów dokumentu, ale również kontekstu jego wykorzystania. Czasem prostota jest najlepsza, innym razem potrzebujemy pełnego odtworzenia, aby zachować integralność przekazu.
Transdoc z FineReader
Konfiguracja FineReadera
Na początek należy upewnić się, że FineReader jest zainstalowany i aktualny. W ustawieniach FineReader, w menu „Narzędzia->Opcje”, znajduje się szereg opcji wymagających zmian. Kluczowe jest ustawienie preferencji językowych. Jeśli praca dotyczy dokumentu w języku polskim, należy wybrać właśnie ten język. Nie jest to jedynie sugestia, ale krytyczna konieczność – im dokładniejsze ustawienia językowe, tym lepsza będzie rozpoznawalność tekstu przez FineReader. Można wybrać kilka języków, ale nie warto z tym przesadzać – za duża ilość języków wpłynie negatywnie na prawidłowość rozpoznawania liter i słów.
Przykładowe ustawienia:
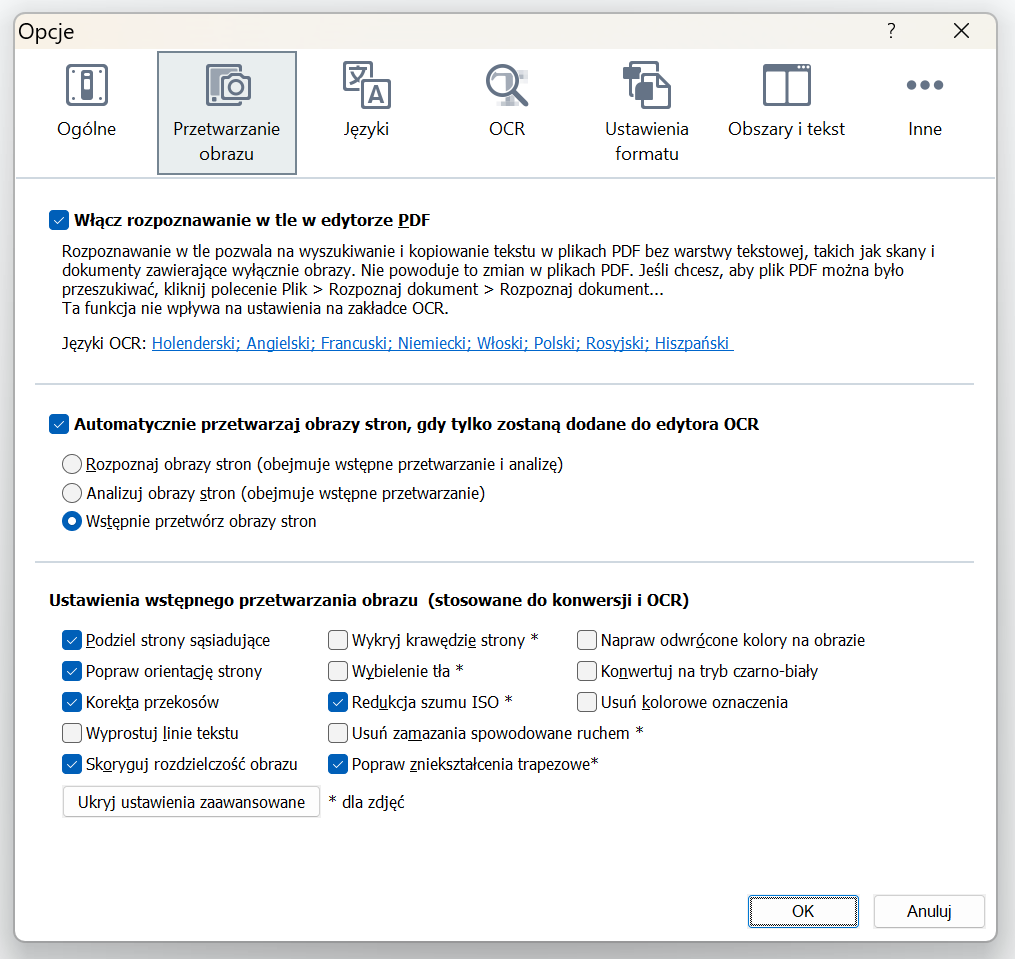
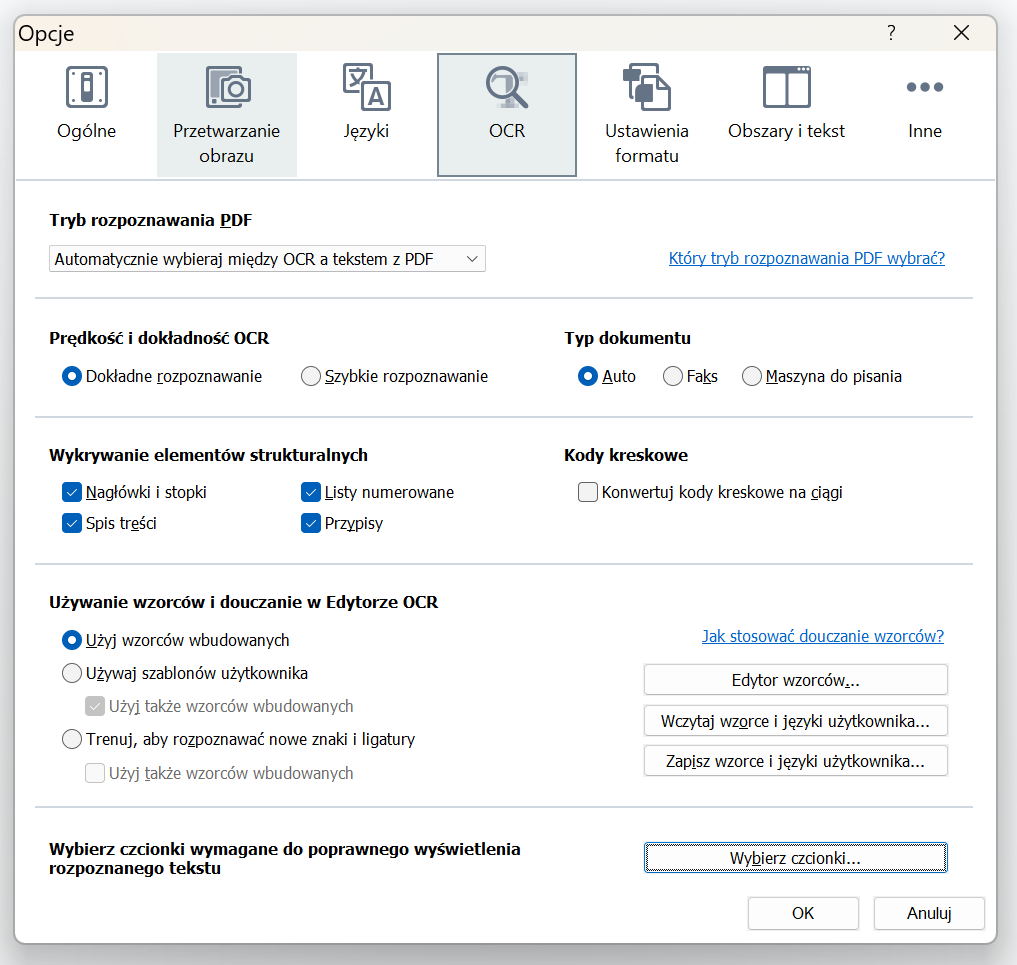
Jeśli nie znasz języka dokumentu, to rozważ włączenie opcji „Zaznacz niepewne znaki” (tylko jeśli nie jest to, co druga litera w zdaniu). Będzie to bodźcem dla tłumacza, by rzucił okiem na oryginalny plik, upewniając się, że OCR jest prawidłowy. Oczywiście zatwierdzamy opcje przyciskiem „OK”.
Kolejnym krokiem jest import nieedytowalnego pliku do Edytora, wstępne rozpoznanie obszarów, poprawienie obszarów, rozpoznanie ich zawartości, poprawienie literówek oraz eksport do DOCX. W Wordzie mamy dwie opcje:
- Posprzątać błędne formatowania po eksporcie, by umożliwić konwersję tekstu na tabelę, wskutek czego wystarczy ją powielić, lewą ukryć i Transdoc gotowy.
- Stworzyć tabelę od początku, po kolei wkleić wyeksportowane teksty do lewej kolumny tej tabeli, a potem ją powielić i lewą ukryć.
Domyślnym skrótem na ukrywanie/odkrywanie treści w MS Word jest CTRL+SHIFT+H.
Rozwiązywanie problemów jest nieuniknioną częścią pracy z technologią. Jedną z najczęstszych przeszkód staje się sytuacja, gdy FineReader nie rozpoznaje określonych czcionek lub stylów w dokumencie. W przypadku Transdoc nie ma znaczenia odwzorowanie fontów, ale ich rozpoznawanie, to już inna sprawa. Jest to zaawansowana funkcjonalność, ale podpowiadamy, że z pomocą przyjdzie Douczanie wzorców (w „Narzędzia->Opcje->OCR”). Rozwiąże to także problem notorycznie błędnie rozpoznawanych konkretnych znaków w dokumencie.
Zaawansowane techniki Transdoc
Dla poszukiwaczy przygód funkcja przetwarzania wsadowego „Hot folder” oferująca możliwość jednoczesnego przetwarzania wielu dokumentów. Funkcja ta pozwala na przetworzenie kilku plików i otrzymanie ich wszystkich gotowych, co znacznie oszczędza czas. Funkcja ta dostępna jest w wyższych wersjach licencji FineReader.
Innym przydatnym narzędziem jest tworzenie własnego języka:
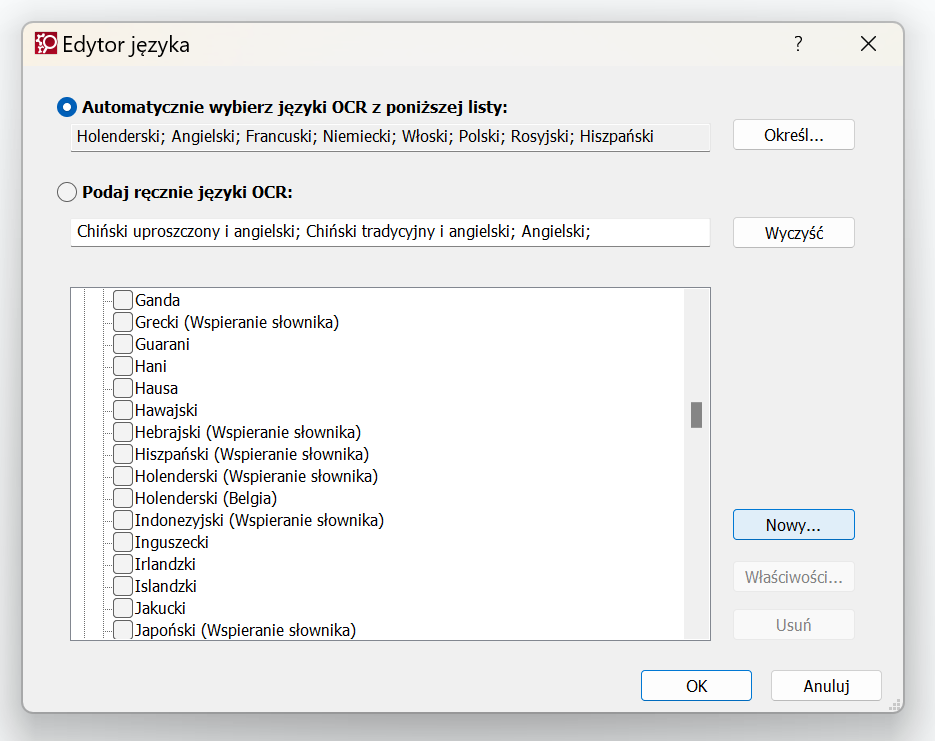
Po kliknięciu „Nowy” wybieramy język bazowy, na podstawie którego tworzymy wariant, a potem możemy wybrać litery alfabetu:
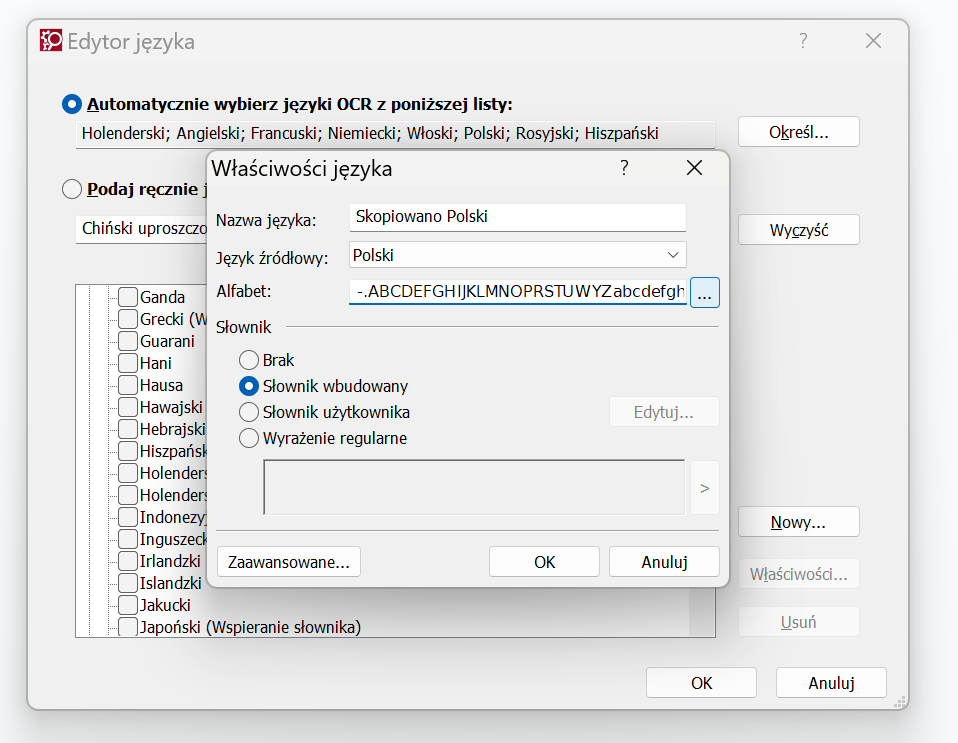
Dzięki temu – w końcu – zaczną rozpoznawać się prawidłowo znaki, które nie chciały rozpoznawać się wcześniej. Oczywiście chodzi o znaki, których nie było domyślnie w danym języku wbudowanym w FineReader. Na przykład, jeśli mamy znaki typu symbole: delta (w sumie całą gamę greckich symboli), średnica, ułamki itp., to one nie będą prawidłowo rozpoznanie, używając domyślnych ustawień. Po kliknięciu „Zaawansowane” mamy jeszcze większą kontrolę nad znakami przypisanymi do danego języka. Język polski domyślnie rozpoznaje następujące znaki:
!”#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]_abcdefghijklmnopqrstuvwxyz{|}~£¥§©«¬®°±»ÓóĄąĆćĘꣳŃńŚśŹźŻż—‘’‛“”„•′€™■□▲△►▻▼▽◄◅◊◎◦★☆♦✓❖
Draft_OCR – proste odwzorowanie
Przed rozpoczęciem OCR konieczne jest odpowiednie przygotowanie dokumentu. Starannie przygotowany materiał źródłowy znacząco zwiększa skuteczność nawet najbardziej zaawansowanego oprogramowania OCR.
Należy upewnić się, że dokument jest zeskanowany w rozdzielczości co najmniej 300 DPI (punktów na cal). Niższe rozdzielczości mogą skutkować rozmytym tekstem, utrudniającym pracę oprogramowania OCR i prowadzącym do niespójnych rezultatów. Istotne jest również usunięcie wszelkich zbędnych elementów, takich jak zagniecenia, znaki wodne, ziarno w tle czy ślady długopisu, które mogłyby zakłócić proces rozpoznawania. Nieraz potrzebny będzie program graficzny np. Photoshop, a innym razem wystarczy np. usunąć znak wodny lub zbędną (drugą) numerację wybierając odpowiednie opcje w edytorze PDF (Acrobat, PDF-XChange Editor itp.).
W FineReaderze zastosowanie mają takie same ustawienia jak wcześniej, ale z jednym wyjątkiem:
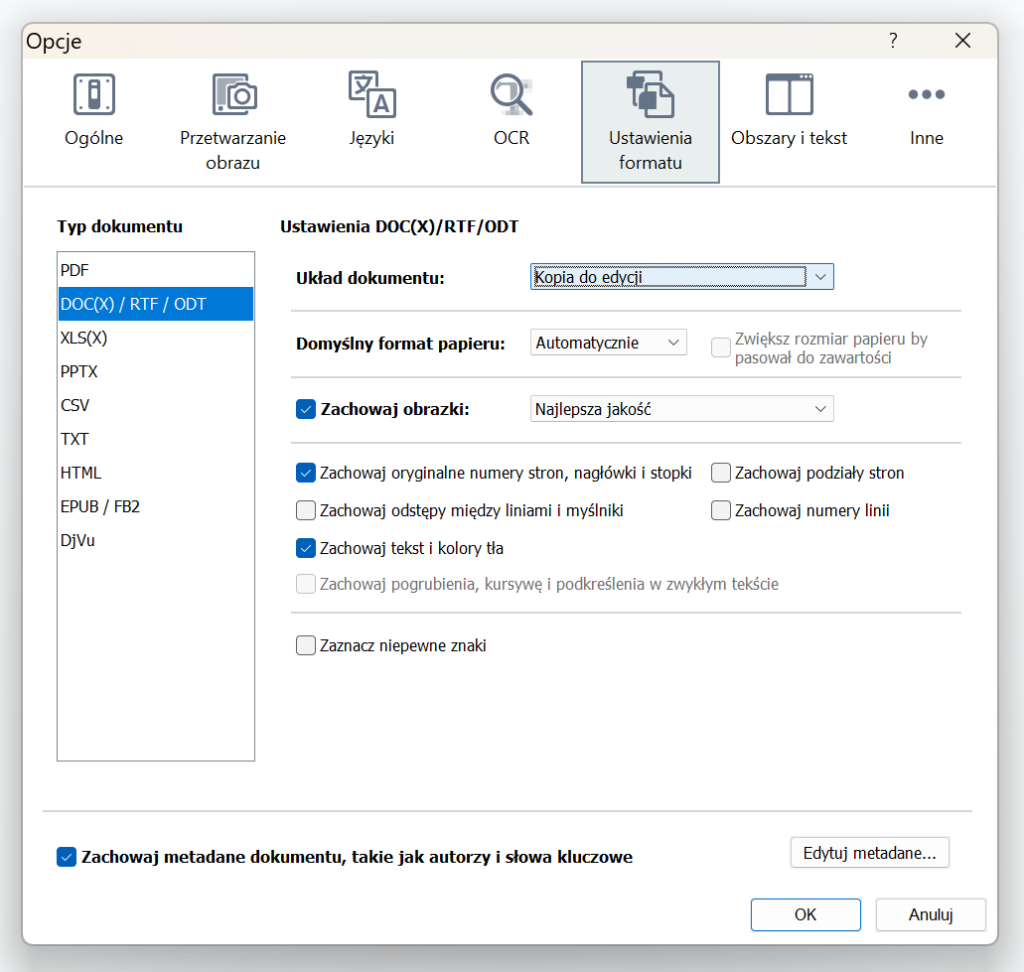
Włączamy zachowanie numerów stron, nagłówków i stopek oraz możemy pokusić się o zmianę układu dokumentu na „Kopia do edycji”. Nie zawsze się to sprawdzi, a raczej wyłącznie w przypadku prostszych układów. Wybierając tę opcję, nic nie tracimy. W razie potrzeby można to zmienić później – bez dodatkowej pracy.
Konwersja do DOCX
Praca z FineReaderem będzie analogiczna, jak wyżej, czyli import nieedytowalnego pliku do Edytora, wstępne rozpoznanie obszarów, poprawienie obszarów, rozpoznanie ich zawartości, poprawienie literówek oraz eksport do DOCX. Jeśli eksport do Worda (gdyż mamy opcję zapisania do DOCX lub wysłania do Worda – można ich używać zamiennie – efekt pracy FineReadera jest taki sam) posiada masę ramek tekstowych lub pól, to oczywiście należy zmienić układ na tekst sformatowany i spróbować ponownie.
Podstawowe formatowanie
Po uzyskaniu edytowalnego tekstu przychodzi czas na jego dopracowanie. Podstawowe formatowanie to etap, na którym możemy tchnąć życie w nasz draft_OCR.
Jak pisaliśmy na początku: w tym przypadku odwzorowuje się oryginalne teksty z zachowaniem logicznego porządku oraz niezbędnych przepływów wraz z formatowaniem lokalnym takim, jak pogrubienia, podkreślenia, indeksy, pismo kursywne (i inne oczywiste wyróżnienia wewnątrz zdania, które mają zastosowanie funkcjonalne).
Na taką okoliczność warto stworzyć sobie arkusz styli, który zawsze importujemy do pliku po OCR i formatujemy nim cały dokument, osiągając, w ten sposób, spójny, czysty i przejrzysty plik przygotowany do tłumaczenia.
W przypadku dokumentów wielojęzycznych należy upewnić się, że języki, które nie będą źródłowym (dla tłumacza), zostaną ukryte na czas tłumaczenia lub zignorowane na etapie przygotowywania OCR.
Bardzo ważne jest, aby usuwać zbędne podziały tzn. twarde entery, bo wpłyną one na segmentację pliku w narzędziu CAT, a tam, gdzie podział jest niezbędny, to zastąpienie twardego entera miękkim. Jeśli jakieś zdania są podzielone twardymi enterami (np. Między stronami), to takie zdania trzeba połączyć w logiczną całość.
Kontrola jakości
Po ukończeniu draft_OCR należy uważnie przeczytać tekst, poszukując typowych błędów związanych z OCR, takich jak błędnie rozpoznane znaki czy nieprawidłowa interpunkcja. Chociaż narzędzia programowe mogą przyspieszyć ten proces, ludzkie oko pozostaje niezastąpione w wykrywaniu subtelnych nieprawidłowości. Stosunkowo niewielu użytkowników FineReadera korzysta z modułu kontroli pisowni wbudowanego w ten program. Rekomenduje się korzystanie z tej funkcjonalności – po to jest – ale, w ostateczności, można ten proces odroczyć i wykonać kontrolę pisowni (F7) w MS Word. Jest to etap, który prędzej, czy później będzie trzeba wykonać.
Wskazówki
W przypadku szczególnie wymagających dokumentów (np. dokumentów liczących setki stron) warto rozważyć podzielenie ich na mniejsze sekcje. Umożliwi to bardziej skoncentrowane rozpoznawanie OCR.
Jeśli podziały stron są istotne, zaleca się użycie podziałów w stylach akapitowych w Wordzie zamiast ręcznych podziałów sekcji.
Nie należy bagatelizować wartości ręcznych poprawek. OCR, choć zaawansowane, nie jest nieomylne. Przygotowanie się na ręczne usuwanie pozostałych niedoskonałości stanowi część profesjonalnego podejścia do procesu.
Pełne odwzorowanie graficzne
Każdy element przygotowań może zadecydować o sukcesie lub porażce. Poświęcenie czasu na eksplorację i zrozumienie ustawień – od podstawowych opcji rozpoznawania języka po zaawansowane narzędzia formatowania (np. wybór fontów*) – przynosi korzyści. Dostosowanie paska narzędzi zwiększa efektywność pracy.
Jakość skanów stanowi fundament udanego OCR. Stosowanie rozdzielczości minimum 300 DPI dla dokumentów tekstowych jest zalecane. Oczywiście nie ma to znaczenia, jeśli pracujemy z plikiem PDF, który skanem nie jest. W przypadku skomplikowanych układów pomocna okazuje się funkcja automatycznego wykrywania struktury dokumentu.
*możemy wybierać spośród fontów zainstalowanych w systemie. Dzięki temu będą użyte już w eksporcie do DOCX.
Lokalizacja grafik
Podstawowe opcje są dwie:
- Nanoszenie pól tekstowych na grafiki zawierające tekst do tłumaczenia.
- Tworzenie mini-transdoc, czyli tabelki-legendy pod grafiką, która wymaga tłumaczenia.
Obydwa warianty wymagają OCR i przygotowania, a o jego wyborze powinien zadecydować klient końcowy lub zleceniodawca.
Alternatywnie można wyeksportować wszystkie grafiki z PDF lub wykonując OCR nie zaznaczać tekstów na grafikach, wyciągając je (grafiki) w niezmienionej formie, aby później rozpakować DOCX (wystarczy zmienić rozszerzenie z DOCX na ZIP) i w podkatalogu word/media znaleźć wszystkie grafiki użyte w dokumencie, w celu ich lokalizacji poza Wordem (np. w Photoshopie).
Optymalizacja pod kątem CAT
OCR dla narzędzi CAT zwiększa efektywność pracy tłumaczy. FineReader pozwala eksportować wyniki do formatów kompatybilnych z systemami CAT. Niestety zdarza się, że eksport posiada zbędne style, „śmieciowe” formatowanie i inne elementy, które przeszkadzają tłumaczowi w pracy, generując zbędne tagi. Wskazane jest, by grafik przygotowujący plik do pracy w CAT posiadał np. Tradosa i mógł podejrzeć, jak wygląda OCR, zanim prześle go dalej. Dzięki temu widać problemy wymagające wyeliminowania przed przekazaniem pliku do kolejnego etapu produkcji. W internecie znajdziemy kilka makr lub skryptów do Worda, które eliminują spore ilości zbędnych tagów np. Codezapper. Należy jednak pamiętać, że każdy tak coś oznacza – usuwając tag, usuwamy coś więcej. Bez możliwości podglądu OCR przed i po usunięciu tagów jest ryzykowne i może się opłacić, ale nie musi. 50 na 50. Zastosowanie mają te same zasady, co wyżej, czyli optymalizacja twardych i miękkich enterów, łączenie podzielonych tekstów, dzielenie tekstów, które powinny być oddzielone, a brakuje podziałów, automatyczne numeracje zamiast ręcznych itd.
Wskazówki
MS Word ma limit wielkości strony – 55,88 cm x 55,88 cm – więc dokumenty o większym formacie, mogą wymagać przeskalowania (zmniejszenia).
Standardowo unika się używania pól tekstowych w OCR, ale schematy elektryczne, rysunki techniczne oraz projekty mogą wymagać użycia pól tekstowych.
Pola tekstowe muszą być właściwie i rozważnie kotwiczone do innych elementów np. akapitu lub strony. W przeciwnym razie, wskutek zmiany długości tekstu (w tłumaczeniu), zmienią swoje położenie. Ma to zastosowanie również do innych elementów graficznych, które występują w plikach o pełnym odwzorowaniu.
Razem z FineReaderem otrzymujemy również Screenshot Reader, który przydaje się do szybkiego, punktowego wyciągania pojedynczych tekstów np. na potrzeby tworzenia legend pod grafikami wymagającymi lokalizacji.
Zdarzają się problemy z ponownym otwarciem wiązki (zapisanego projektu FineReadera), więc rekomenduje się zakończenie prac nad otwartym dokumentem bez zamykania i ponownego otwierania FineReadera.
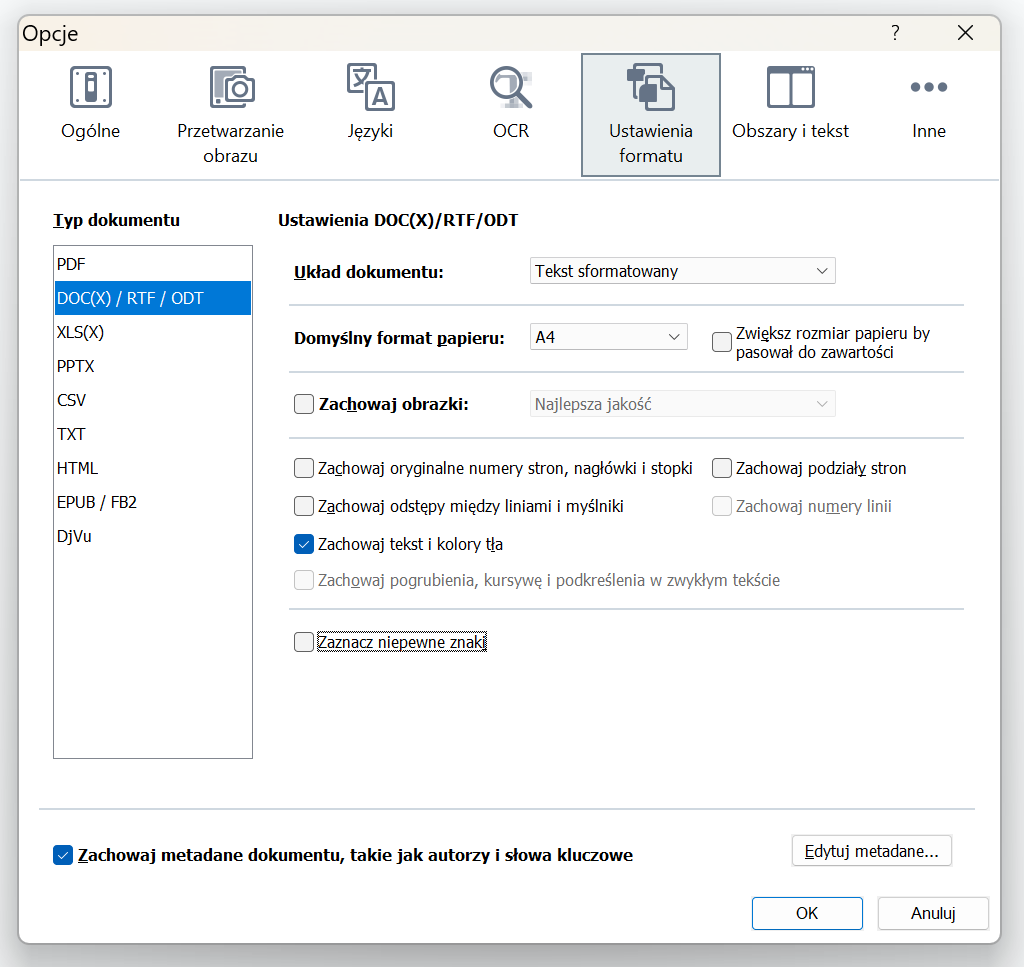
W ustawieniach formatu możemy wybrać niestandardowe ustawienia zapisywanych grafik, by wybrać między innymi stopień ich kompresji (Jakość):
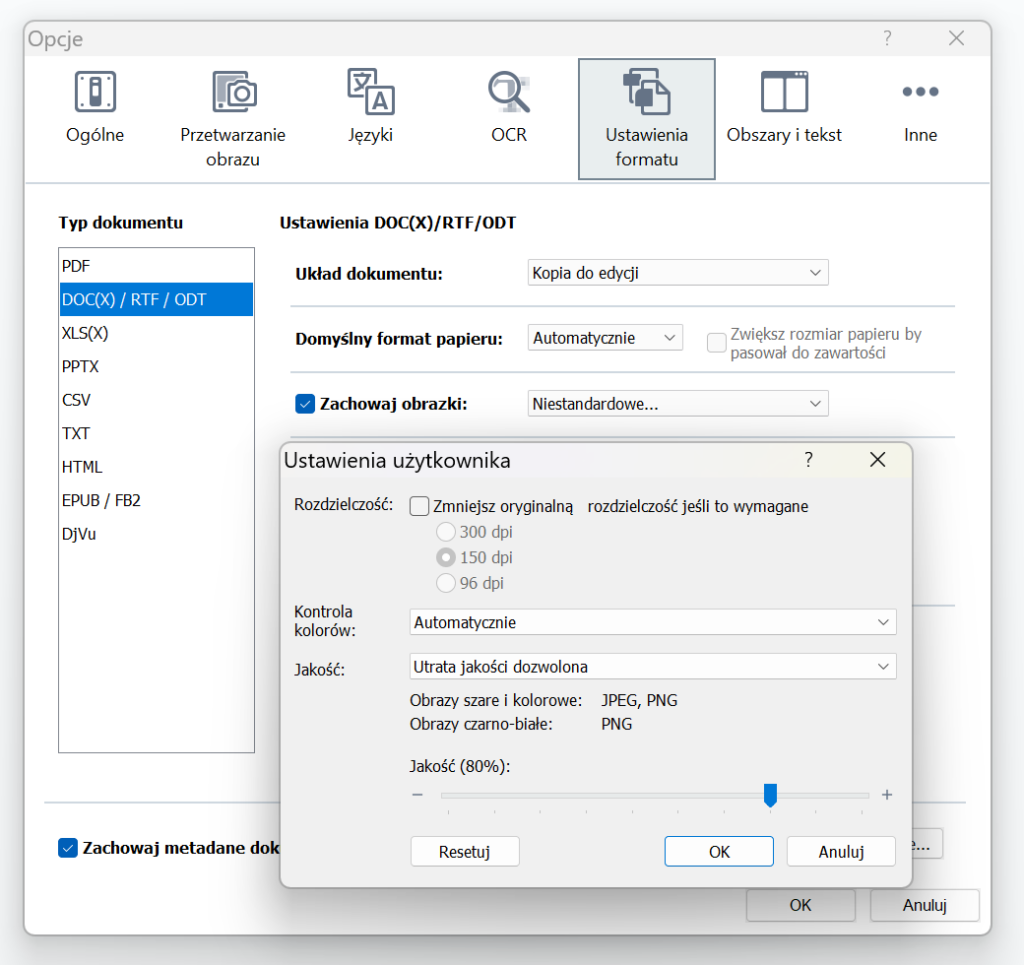
Może się to przydać w przypadku dokumentów o dużej ilości grafik oraz stron, by uniknąć Worda „ważącego” kilkaset MB.
Korzyści płynące z doskonałego OCR
Dokładność stanowi fundament każdego udanego projektu tłumaczeniowego – cecha nadająca słowom znaczenie. Perspektywa odszyfrowywania nieczytelnej strony lub czytania tłumaczenia pełnego błędów nie jest atrakcyjna dla nikogo. Wzrost dokładności przekłada się na większe zadowolenie klientów. Efektywny proces OCR może znacząco skrócić czas realizacji projektu. Tłumacze, którzy umiejętnie wykorzystują zaawansowane techniki OCR, są w stanie osiągnąć imponującą wydajność bez kompromisów w zakresie jakości, przy okazji zyskując dodatkową przewagę konkurencyjną.
Korzyści z efektywnego OCR wykraczają poza indywidualnych tłumaczy czy klientów, wpływając pozytywnie na całą branżę. Wyższa jakość prowadzi do mniejszej liczby korekt i poprawek, przyspieszając harmonogramy projektów i umożliwiając podejmowanie nowych zadań. Firmy o usprawnionej organizacji pracy są lepiej przygotowane do efektywnego rozwiązywania problemów, co przekłada się na ich konkurencyjność na rynku.
Idea jest prosta: bezbłędne przygotowanie procesów OCR poprawia każdy aspekt pracy tłumaczeniowej. Prawidłowo sformatowane dokumenty, bezbłędne teksty i bezproblemowa integracja oznaczają mniejszą presję na wszystkie zaangażowane strony, tworząc środowisko sprzyjające innowacjom i współpracy. Osiągnięcie tego poziomu jakości wymaga staranności i przemyślenia, ale efekty są warte wysiłku.
Najlepsze praktyki OCR
- Zanim rozpocznie się OCR, należy odpowiednio przygotować dokument. Zły stan dokumentu może nie tylko utrudnić pracę oprogramowania, ale także doprowadzić do frustracji podczas dalszej obróbki.
- Oceń jakość dokumentu źródłowego. Jeśli jest w złym stanie, zajmij się jego poprawą lub poproś o lepszą kopię. Upewnij się, że strony są płaskie, czyste i pozbawione zagnieceń czy plam. Podczas digitalizacji dokumentu papierowego, użyj skanera z minimalną rozdzielczością 300 DPI, aby uzyskać optymalną ostrość.
- Nadaj dokumentowi logiczną strukturę, jeśli jej brakuje. Ponumeruj strony, dodaj nagłówki i usuń wszelkie niepotrzebne elementy. Spójne przedstawienie dokumentu znacząco ułatwia pracę oprogramowania OCR.
- Każde oprogramowanie OCR ma swoje unikalne mocne i słabe strony. Kluczowe jest przeanalizowanie konkretnych potrzeb projektu. Narzędzia takie jak ABBYY FineReader doskonale radzą sobie z formatowaniem całych stron i interpretacją tabel – idealne do tłumaczenia obszernych raportów. Z kolei prostsze aplikacje mogą zapewnić szybkie wyniki, ale brakuje im precyzji w przypadku złożonych układów tekstu lub wielu języków.
- Korekta OCR wymaga precyzji i cierpliwości. OCR nieuchronnie popełnia błędy; niektóre litery lub liczby mogą zostać nieprawidłowo rozpoznane, a interpunkcja może wymagać korekty.
- Najlepszą praktyką jest porównywanie oryginalnego dokumentu z wynikiem OCR, strona po stronie. Może to wydawać się żmudne, ale zaniedbanie tego etapu może skutkować kosztownymi błędami, szczególnie w przypadku dokumentów technicznych lub prawnych.
Optymalizacja plików DOCX dla narzędzi CAT
Znajomość specyficznych wymagań wybranego narzędzia CAT jest fundamentem skutecznej optymalizacji. Każde oprogramowanie ma swoje unikalne cechy i ograniczenia, które należy uwzględnić.
Większość narzędzi CAT radzi sobie dobrze z plikami DOCX, jednak kluczowe jest zrozumienie ich specyfiki. Niektóre mogą mieć trudności z zaawansowanym formatowaniem lub osadzonymi obiektami. Warto dokładnie zapoznać się z dokumentacją techniczną oprogramowania, aby zidentyfikować jego możliwości i ograniczenia.
Szczególną uwagę należy zwrócić na zachowanie stylów, nagłówków, stopek i osadzonych obrazów po przetworzeniu przez narzędzie CAT. Dokładne zrozumienie tych aspektów pozwoli uniknąć nieprzyjemnych niespodzianek w trakcie procesu tłumaczenia.
Ustawienia segmentacji
Właściwe ustawienia segmentacji są kluczowe dla płynności procesu tłumaczenia. Umożliwiają one wyraźne oddzielenie segmentów tekstu, które narzędzie CAT będzie przetwarzać w formie jednostek tłumaczeniowych w celu zapisania w bazie tłumaczeniowej.
Większość narzędzi CAT oferuje domyślne reguły segmentacji, które można dostosować do struktury konkretnego dokumentu. Warto rozważyć modyfikację ustawień segmentacji w zależności od typu dokumentu i jego specyfiki. No tak, ale miało być o dostosowywaniu plików DOCX do CAT, a nie odwrotnie. Zgadza się! Aby tak zrobić, najpierw trzeba zrozumieć, jakie są te domyślne reguły segmentacji, aby grafik mógł przygotować plik, zachowując zgodność z tymi regułami. Na przykładzie Tradosa (kluczowe zasady dzielenia segmentów dla plików DOCX):
- Kropki: segmentacja na końcu zdania, kiedy kropka jest zakończona białym znakiem, np. „To jest zdanie. To jest kolejne zdanie”.
- Wykrzykniki: segmentacja po wykrzykniku, np. „Uwaga! To jest ważne”.
- Znaki zapytania: segmentacja po znaku zapytania, np. „Czy to działa? Tak, działa”.
- Średniki: średniki mogą, ale nie muszą, inicjować dzielenia, w zależności od ustawień, np. „To jest przykład; to również jest przykład”.
- Podziały akapitów: każdy nowy akapit zazwyczaj zaczyna nowy segment.
- Cudzysłowy i nawiasy: tekst zamknięty w cudzysłowach lub nawiasach jest traktowany jako część bieżącego segmentu, chyba że kończy się kropką, wykrzyknikiem lub znakiem zapytania.
Tagi
Odpowiednie tagowanie pliku DOCX zwiększa przejrzystość i zapewnia płynniejszy proces tłumaczenia. Tagi działają jak drogowskazy, prowadząc tłumacza przez dokument i zabezpieczając formatowanie treści.
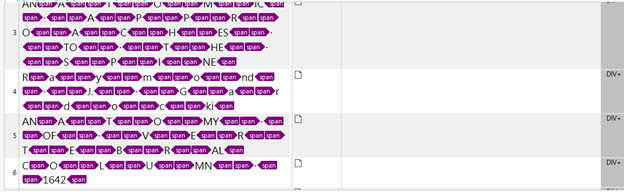
Wiele narzędzi CAT wykorzystuje tagi do identyfikacji elementów wewnątrz linii, takich jak pogrubienia, kursywa czy hiperłącza. Istotne jest, aby tagi były prawidłowo umieszczone i sformatowane. Przygotowując plik DOCX, należy upewnić się, że tagi odpowiadają zamierzonemu formatowaniu. Na przykład, jeśli fraza w tekście źródłowym jest pogrubiona, odpowiedni tag w DOCX powinien to odzwierciedlać, aby zachować takie samo wyróżnienie w tłumaczeniu. Zbędne taki potrafią katastrofalnie wpłynąć na wydajność tłumacza, a reperkusje przekroczonych terminów mogą być dotkliwe.
Przykład zbędnych tagów (źródło: community.rws.com):
Przygotowanie glosariuszy i pamięci tłumaczeniowych
OCR można również wykorzystać do stworzenia wielojęzycznego glosariusza lub bazy pamięci tłumaczeniowej (z wcześniej wykonanych tłumaczeń). Dzięki OCR możliwe jest szybkie i efektywne wyodrębnienie tekstu z wcześniej przetłumaczonych dokumentów, co pozwala na ich dalsze wykorzystanie. Przykładowo można stworzyć glosariusz z 8-języcznej deklaracji zgodności lub 4-języcznego katalogu części w celu spójnego tłumaczenia tych samych fraz w przyszłości. Jeśli chodzi o bazy tłumaczeniowe, to może się zdarzyć, że klient będzie zmieniał biuro tłumaczeń. Od poprzedniego biura nie dostanie swoich baz tłumaczeniowych, a wie, że w jego tekstach jest dużo powtórzeń, za które wolałby nie płacić ponownie, co jest oczywiste. W takim wypadku może dostarczyć „stare” PDFy – źródłowe oraz przetłumaczone – z których wykonuje się OCR, a potem bazę tłumaczeniową, która jest wykorzystywana do podnoszenia jakości oraz redukcji kosztów we współpracy z nowym biurem tłumaczeń.
QA przed importem do narzędzia CAT
Wykonywanie końcowej kontroli przed importem pliku DOCX po OCR do narzędzia CAT jest kluczowe. Etap ten można porównać do próby generalnej przed występem – upewniamy się, że wszystkie elementy są na swoim miejscu i gotowe do działania.
Należy zwrócić szczególną uwagę na:
- niechciane, często wielokrotne spacje,
- niespójności w typografii (różne rozmiary lub style fontów),
- nadgorliwe podziały wierszy,
- literówki i błędy OCR,
- pominięte/nieprzygotowane elementy graficzne.
Przeprowadzenie dokładnego sprawdzenia dokumentu nie tylko zwiększy pewność co do jego należytej jakości, ale może również ujawnić obszary wymagające dalszych korekt.
Pamiętaj, że niektóre problemy można rozwiązać dużo szybciej i efektywniej na wczesnym etapie, a później będzie tylko gorzej. Błędy w dokumencie tłumaczonym docelowo na 27 języków będzie trzeba poprawić 27 razy w przetłumaczonych plikach!
Kluczowe wnioski
Dla profesjonalistów w dziedzinie tłumaczeń i projektowania graficznego kluczowe jest przyjęcie strategicznego podejścia do rozwiązań OCR. Umiejętność krytycznej oceny i efektywnego wykorzystywania narzędzi OCR oraz AI staje się niezbędna. Współpraca z dostawcami usług OCR może prowadzić do rozwoju bardziej zaawansowanych i dostosowanych narzędzi. Aktywny udział w kształtowaniu tych technologii pozwoli na lepsze dostosowanie ich do potrzeb branży.
Przyszłość OCR oferuje ekscytujące możliwości dla tłumaczy i grafików. Aktywne zaangażowanie w rozwój tych technologii pozwoli na wykorzystanie ich potencjału przy jednoczesnym zachowaniu wysokich standardów jakości i kreatywności w pracy.
Kontakt

Kompetencje a kwalifikacje tłumacza: jak oceniać dostawcę usług językowych w projektach B2B (jakość, ryzyko, zgodność)

Ewolucja dużych modeli językowych (LLM) w branży tłumaczeń

Recertyfikacja ISO 17100 – gwarancja jakości usług tłumaczeniowych translax

Tłumaczenia oznaczeń przeciwpożarowych w kontekście norm NFPA

Post-editing (Post-edycja / PE) – niezbędny składnik tłumaczenia maszynowego
Obsługujemy języki
Cookies
Strona wykorzystuje tylko niezbędne ciasteczka techniczne do obsługi sesji i ochrony formularzy; reCAPTCHA i Przelewy24 przetwarzają dane u siebie zgodnie ze swoimi politykami, a my nie zbieramy ani nie profilujemy danych osobowych. Więcej: Polityka prywatności/RODO.



